向量化基础
约 1969 个字 15 行代码 8 张图片 预计阅读时间 13 分钟
NumPy
NumPy 是 Python 中科学计算的基础包,其核心使 ndarray 对象,这封装了同质数据类型的 n 维数组。数组通常是相同类型和大小的项目的固定大小容器。数组中的维数和项数由其形状定义。数组的形状是指定每个维度带下的非负整数元组。在 Numpy 中,维度称为轴。
-
NumPy的部分功能如下:
- ndarray,⼀个具有⽮量算术运算和复杂⼴播能⼒的快速且节省空间的多维数组。
- ⽤于对整组数据进⾏快速运算的标准数学函数(⽆需编写循环)。
- ⽤于读写磁盘数据的⼯具以及⽤于操作内存映射⽂件的⼯具。
- 线性代数、随机数⽣成以及傅⾥叶变换功能。
- ⽤于集成由C、C++、Fortran等语⾔编写的代码的A C API。
基于 NumPy 的算法要比纯 Python 快10到100倍,并且使用内存更少。
| Python | |
|---|---|
上述是一个纯 Python 的例子,做了一个简单的矩阵相加,一个显著特点是大量使用 for 循环,这会造成极大的浪费。我们知道,对于一个矩阵,其位置的运算和其他位置都没有关系,于是我们只需要关心这个位置上的行为。假如对于如上 3*3 的矩阵我们有九个核心,那么我们就可以使每个核心处理一个位置,这样可以实现非常高效的并行计算。对于简单的矩阵相乘的问题,假定两个矩阵分别为 \(m\times k\) 和 \(k\times n\) ,线性代数告诉我们,对于矩阵 \((i,j)\) ,他是由两个一维向量的相乘的结果,其分别对应矩阵的第 \(i\) 行和第 \(j\) 列。因此,此时我们依旧可以让每个核心处理一个位置。
Warning
但是如果有依赖关系的话就必须考虑顺序,同步或者锁了
如果从矩阵退化到向量时,比如两个特别长的 1 维向量相乘,我们可以让核心分头计算不同位置的乘积,然后把这些结果累加起来,也就是说乘法是并行的,加法是串行的。总的来说,我们希望计算能够同时进行从而提高效率,也就是并行。
向量化的核心思想:一次同时参与运算的不是一个值,而是同时多个值一起算,即一个向量
NumPy 的基础知识:NumPy:初学者的绝对基础_Numpy中文网
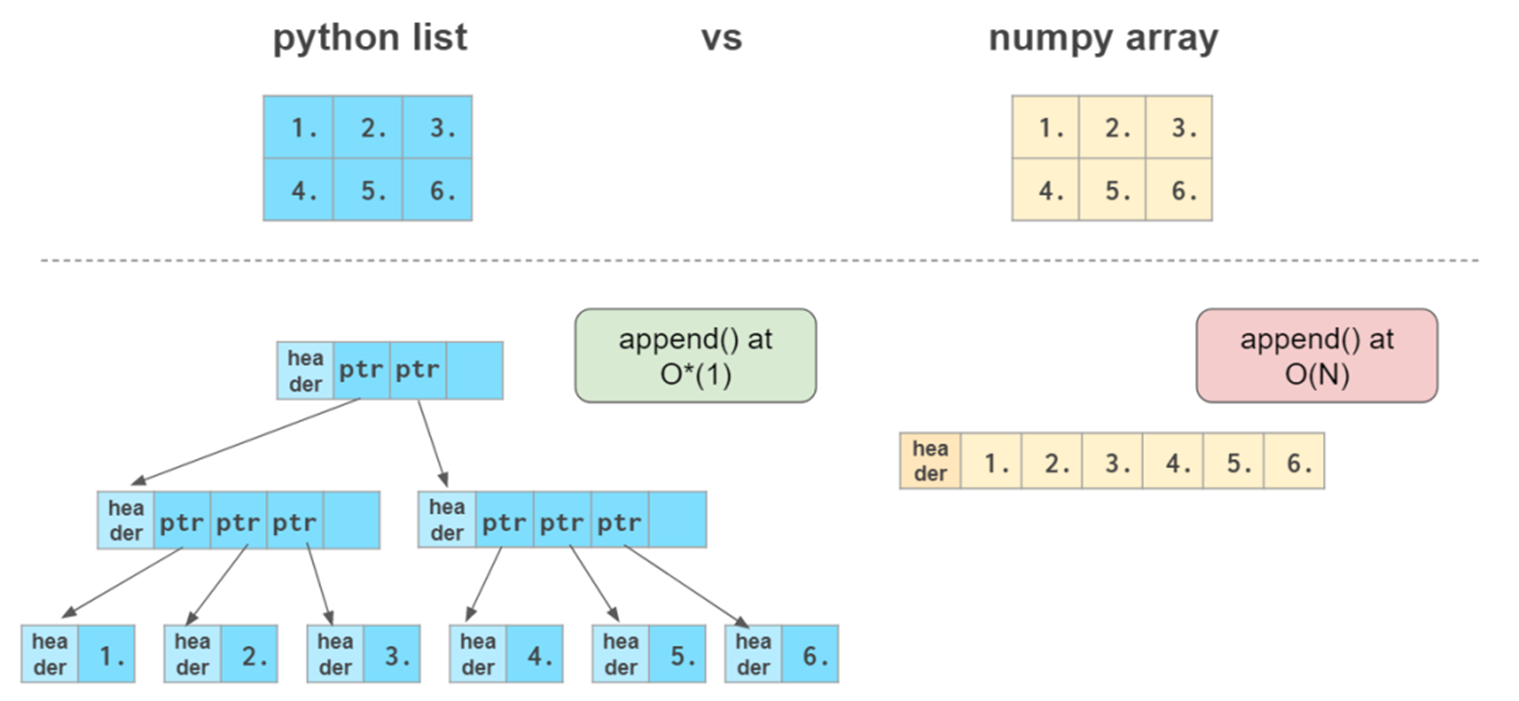
虽然 Python 列表可以在单个列表中包含不同的数据类型,其实质上保存的是指针,而指针可以指向任何数据,这会导致调用列表是进行了寻址操作,降低运算效率。但 NumPy 数组中的所有元素都应该是同类的。如果数组不是同质的,则对数组执行的数学运算将非常低效。
Python list 本身就已经提供了比较强大的索引功能,但维度多了以后,Python list 的索引和 C array 更像,而 Numpy 使用逗号来分割维数,更方便。
一些 NumPy 的使用
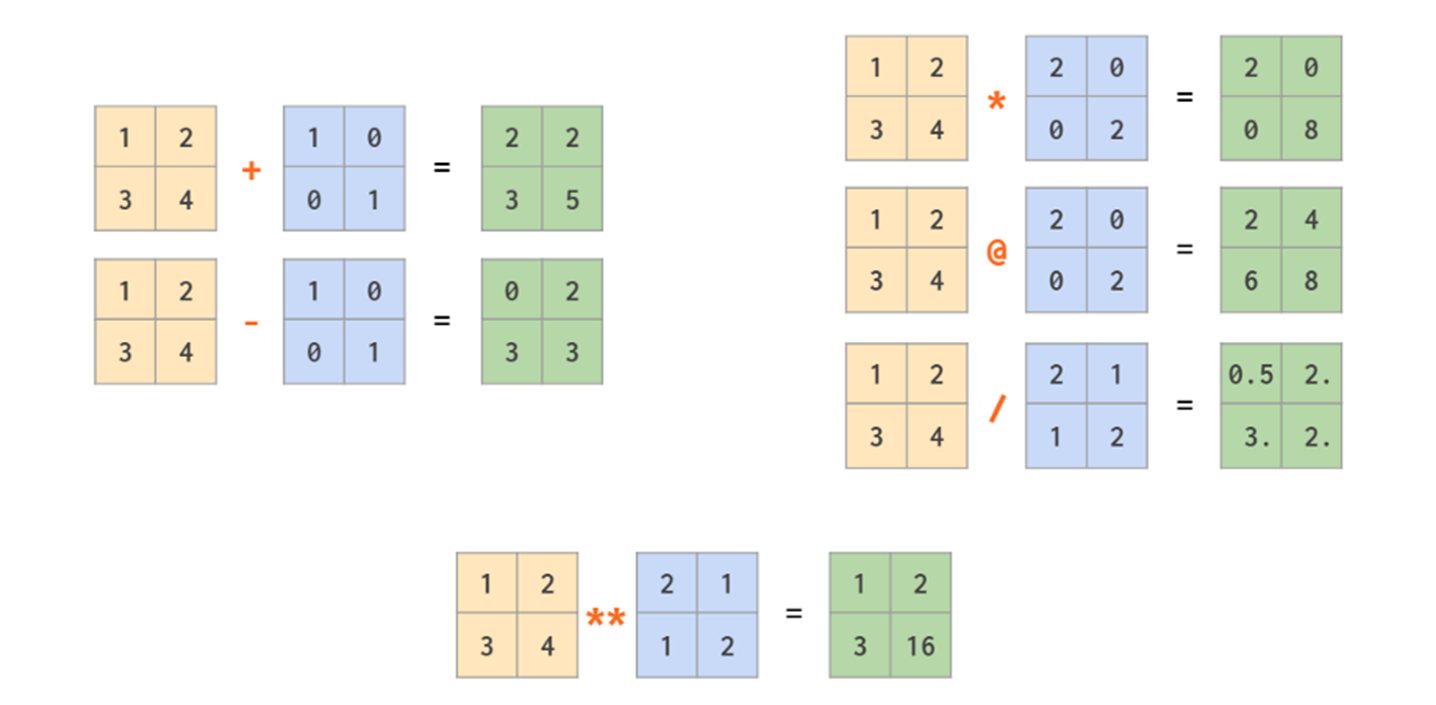
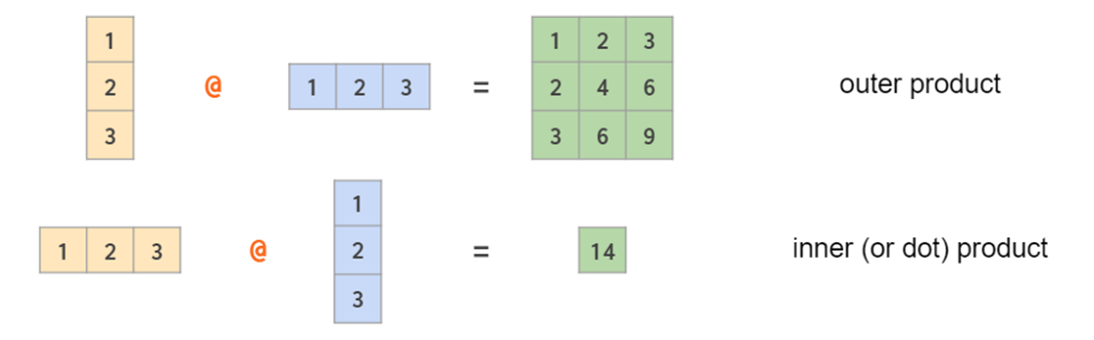
*就是按位乘,@则是传统的矩阵乘法
广播机制:当尺寸不匹配的时候可以将“小”的广播到“大”的尺寸上


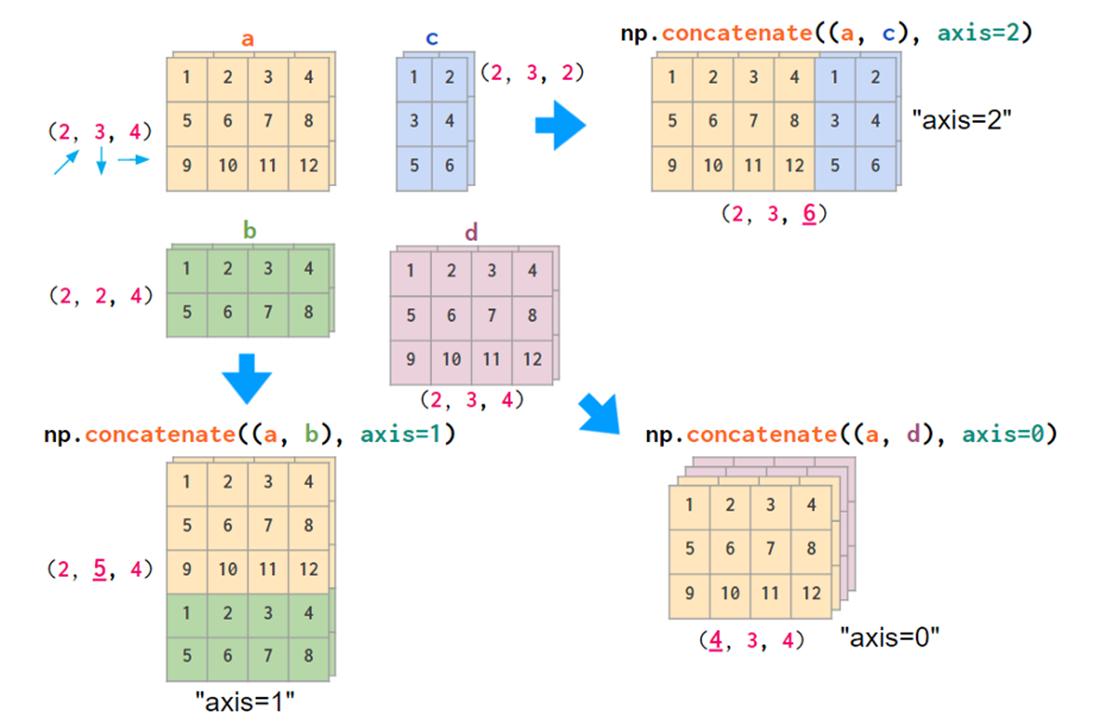
concatenate() 函数:
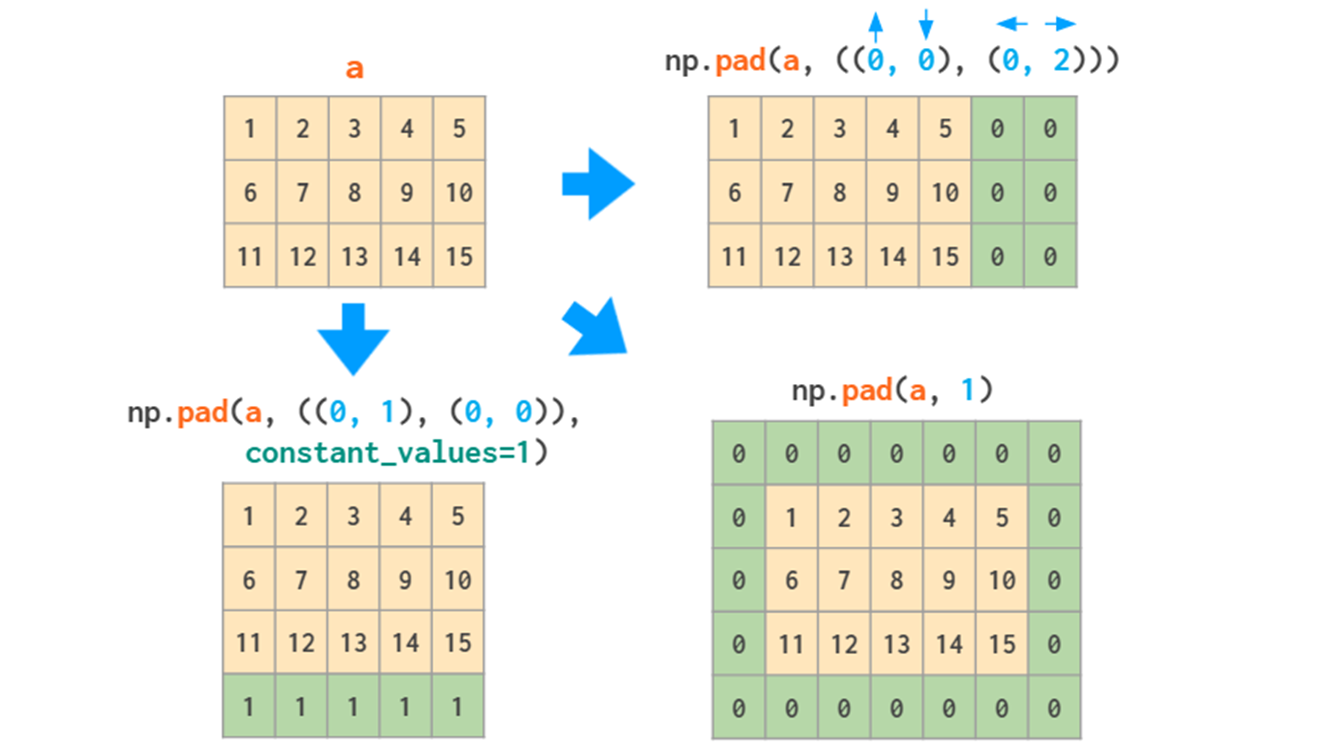
np.pad 用于矩阵拓展,在卷积操作有很大的用处。
Python 为了可读性牺牲了速度(很慢),NumPy 为了速度牺牲了可读性。例如如下代码:
| Python | |
|---|---|
这个代码看起来非常复杂,尽管我们使用了 NumPy ,实际上这只是做了一件简单的事情:寻找 seq 里面有没有 sub 这个字串,并返回每个起始下标。那么这段代码对应一个简单的 Python 语言:
| Python | |
|---|---|
手写 SIMD 向量化
手写 SIMD 向量化兼顾了速度和可读性。单指令多数据流(Single Instruction Multiple Data)在硬件层面上提供了通过一条指令运行多个运算的方法,这个指令是汇编层次上的指令。在操作SIMD指令时,一次性把多条数据从内存加载到宽寄存器中,通过一条并行指令同时完成多条数据的计算。例如一个操作32字节(256位)的指令,可以同时操作8个int类型,获得8倍的加速。同时利用SIMD减少循环次数,大大减少了循环跳转指令,也能获得加速。在 x86 架构下,SIMD 一半和 SSE 和 AVX 等指令集联系在一起,SSE 和 AVX 指令集中提供了大量可以单指令操作多个数据单元的指令,主要以 AVX 为主。
编译器通过SIMD加速的原理是:通过把循环语句展开,减少循环次数,循环展开的作用是减少循环时的跳转语句,跳转会破坏流水线;而流水线可以预先加载指令,减少CPU停顿时间,因此减少跳转指令可以提升流水线的效率。
SIMD 直觉上可以极大地提升效率,但实际情况比较复杂,比如内存带宽使用、解码消耗等,需要具体问题具体分析,并不代表可以同时操作两个数据,加速比就是 2。
一条AVX2指令能处理256位的数据,一条AVX512指令一次能处理512位数据。但指令并不是越长越好,因为指令的功能是需要硬件实现的,一条指令处理8个double就意味至少需要8个double的运算单元,这意味着更大的面积,更高的成本,更多的损耗。
对于 ARM 架构,有专门的指令集。
尽管编译器能够直接优化 SIMD 指令,但有时候代码逻辑逻辑比较复杂,存在循环或分支情况,if 语句无法识别向量化操作,此时就需要我们手写向量化指令。
手写 SIMD 的唯一方法就是查文档
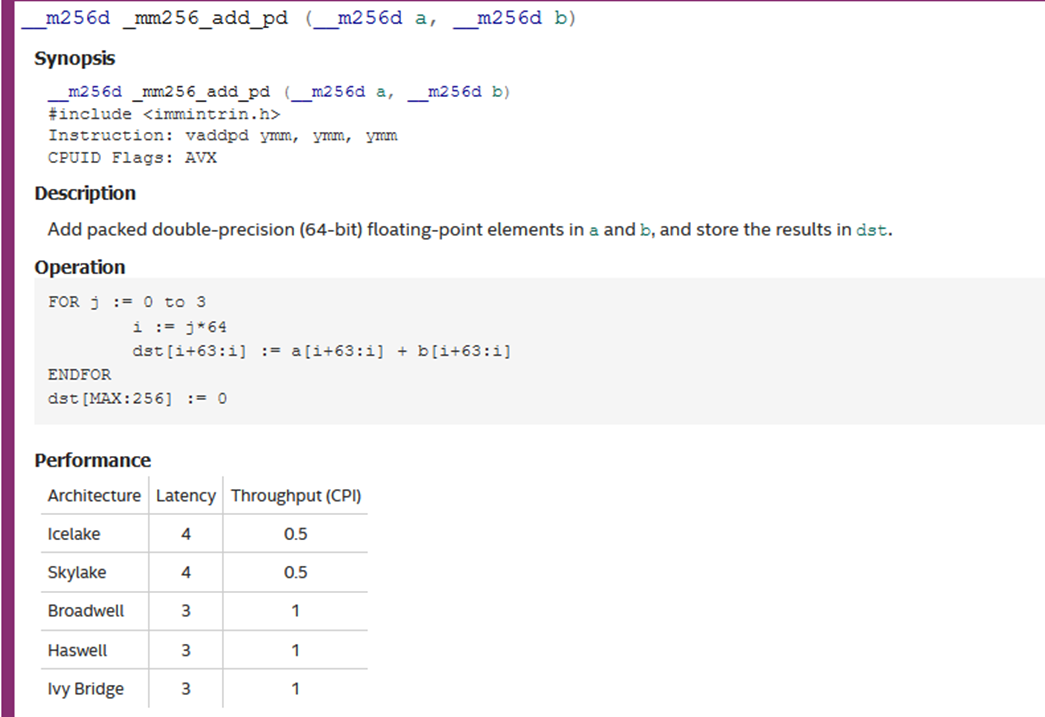
__m256d _mm256_add_pd (__m256d a,__m256d b)这个指令表示数据相加。__m256d两条下划线表示数据类型,256 表示 256 bits指令,d 表示 double 数据。 _mm256_add_pd 表示相加操作,一条下划线表示指令操作(指令类型_操作_单元类型)pd 表示 double 类型数据
| 16字节 | 32字节 | 64字节 | |
|---|---|---|---|
| 32位float | __m128 | __m256 | __m512 |
| 64位float | __m128d | __m256d | __m512d |
| 整型数 | __m128i | __m256i | __m512i |
编写向量化代码的时候请不要相信 ChatCPT
手写向量化顺序很重要。顺序会影响一定的性能损耗,尽管损耗不是很大。
如何把大象装进冰箱
- Load需要计算的数据到向量寄存器
- 进行需要的向量化计算
- Store将向量寄存器的数据存回内存
问题:
- 内存对齐:地址不对齐(数据类型不对),内存对齐能够加速
- 循环边界不确定:SIMD 需要处理“成批”数据,若循环长度不确定或不能整除批处理大小会影响性能。需要能够计算出的可知的边界
- 循环分支的开销掩盖了SIMD提升:分支的跳转成本会掩盖 SIMD 本身带来的性能提升,循环展开,把一个小循环重复写成多次执行,减少跳转次数
- 寄存器数量超限——区分计算和存储的寄存器。一般默认16个256位寄存器进行考量
Important
一定要在最后再进行手写SIMD优化
我们的优化尽可能从算法本身取改进,一切凭感觉