Training Neural Networks Ⅱ
约 3149 个字 16 张图片 预计阅读时间 21 分钟
Previous lecture : Trarining Neural Networks Ⅰ
Learning Rate Schedules
回忆我们所接触的优化方法,他们都将学习率(learning rate)作为超参数(hyperparameter)。在深度学习过程中,学习率可以说是最重要的一个超参数,学习率的设置尤为重要,决定了模型的学习速度与效果。
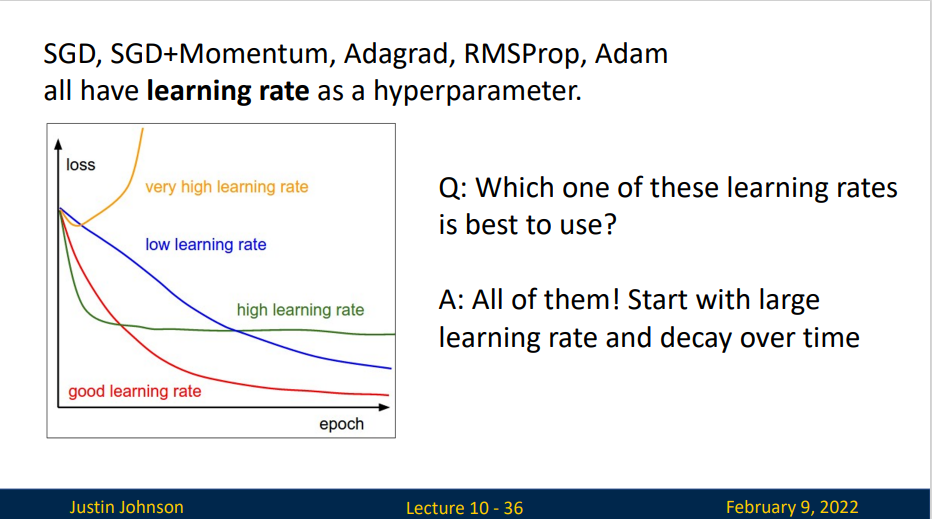
到目前为止,我们主要关注如何更新权重向量的优化算法,而不是它们的更新速率。 然而,调整学习率通常与实际算法同样重要,有如下几方面需要考虑:
- 首先,学习率的大小很重要。如果它太大,优化就会发散;如果它太小,训练就会需要过长时间,或者我们最终只能得到次优的结果。我们之前看到问题的条件数很重要。直观地说,这是最不敏感与最敏感方向的变化量的比率。
- 其次,衰减速率同样很重要。如果学习率持续过高,我们可能最终会在最小值附近弹跳,从而无法达到最优解。简而言之,我们希望速率衰减,但要比\(\mathcal{O}(t^{-\frac{1}{2}})\)慢,这样能成为解决凸问题的不错选择。
- 另一个同样重要的方面是初始化。这既涉及参数最初的设置方式,又关系到它们最初的演变方式。这被戏称为 预热(warmup),即我们最初开始向着解决方案迈进的速度有多快。一开始的大步可能没有好处,特别是因为最初的参数集是随机的。最初的更新方向可能也是毫无意义的。
- 最后,还有许多优化变体可以执行周期性学习率调整。我们建议读者阅读 (Izmailov et al., 2018)来了解个中细节。例如,如何通过对整个路径参数求平均值来获得更好的解。
Learning Rate Decay
步进式递减的方式,就是在某些节点上降低学习率,比如说ResNet这种,就是每三十轮训练就会学习率变为原来的十分之一。可以看到,实际上每次步进后的第20-30个epoch,网络就会再次进入一个稳定状态,然后再一次进行学习率衰减,就可以重新进入一个相对快速的学习状态
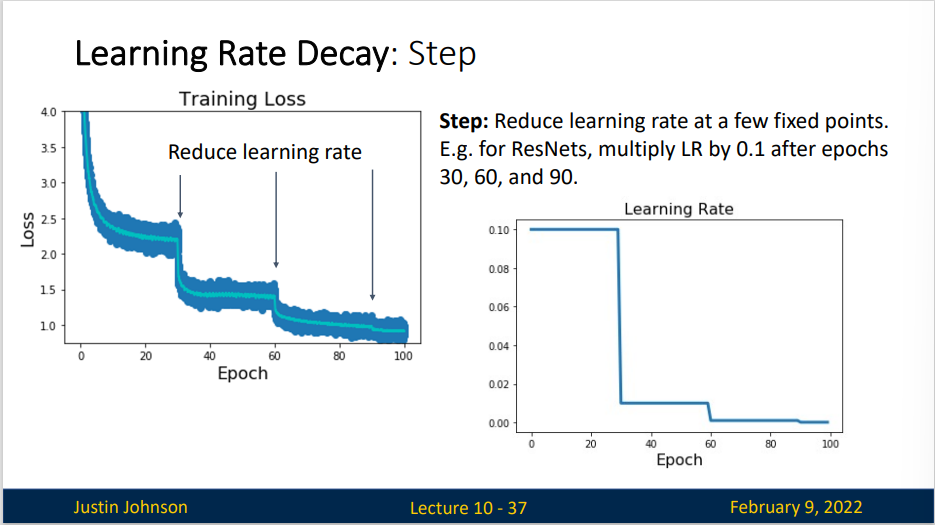
余弦衰减是 (Loshchilov and Hutter, 2016)提出的一种启发式算法。 它所依据的观点是:我们可能不想在一开始就太大地降低学习率,而且可能希望最终能用非常小的学习率来“改进”解决方案。 这产生了一个类似于余弦的调度,函数形式如上所示,学习率的值在\(t∈[0,T]\)之间。
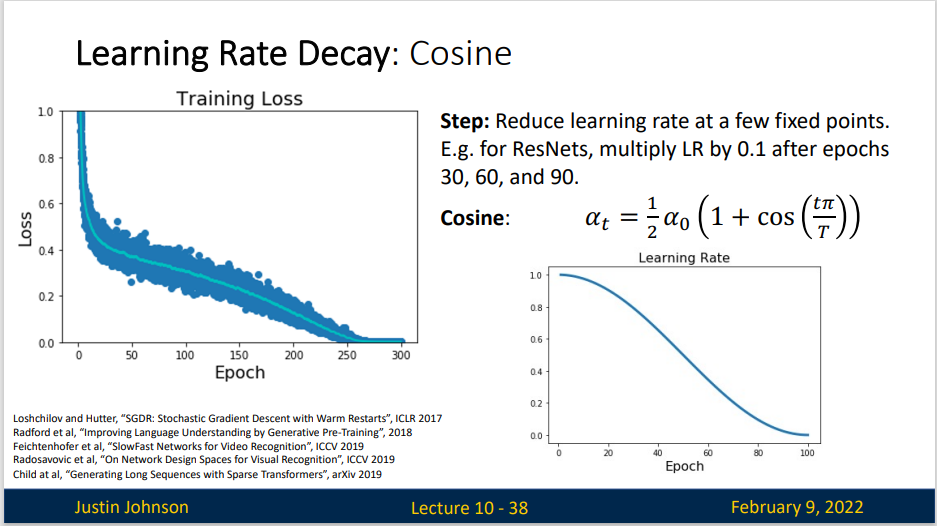
线性衰减非常简单。
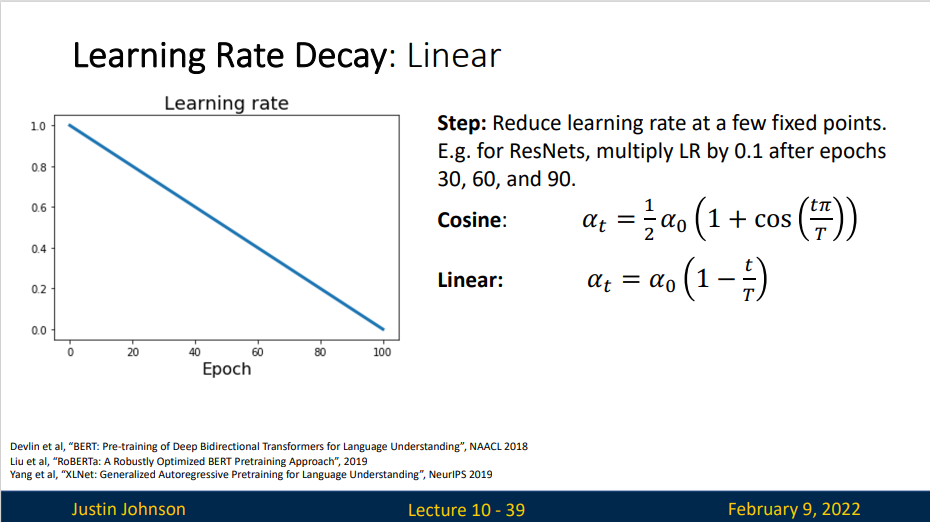
这是在2017年提出的一种算法,存在的缺陷是,模型实际上在最初的高学习率上花费的时间少,在后面的低学习率上花费较多时间,而其他的衰减方案往往在初始的高学习率上花费更多时间,容易导致最开始的时候模型收敛缓慢
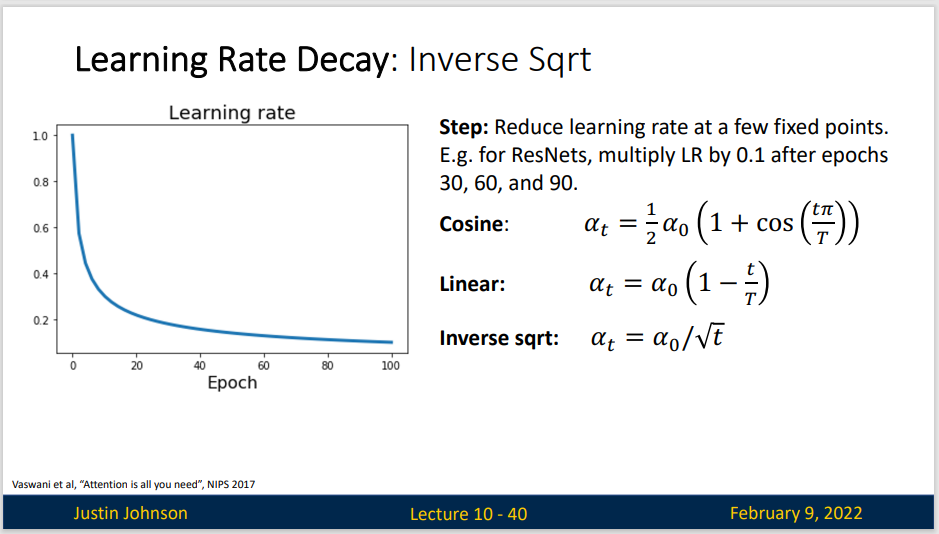
如果我们使用的如RMSProp Adam 这样的复杂的优化算法,仅使用恒定的学习率就可以走很远。
在某些情况下,初始化参数不足以得到良好的解。 这对某些高级网络设计来说尤其棘手,可能导致不稳定的优化结果。 对此,一方面,我们可以选择一个足够小的学习率, 从而防止一开始发散,然而这样进展太缓慢。 另一方面,较高的学习率最初就会导致发散。
解决这种困境的一个相当简单的解决方法是使用预热期,在此期间学习率将增加至初始最大值,然后冷却直到优化过程结束。 为了简单起见,通常使用线性递增。 这引出了如下表所示的时间表。
预热可以应用于任何调度器,而不仅仅是余弦。 有关学习率调度的更多实验和更详细讨论,请参阅 (Gotmare et al., 2018)。 其中,这篇论文的点睛之笔的发现:预热阶段限制了非常深的网络中参数的发散程度 。 这在直觉上是有道理的:在网络中那些一开始花费最多时间取得进展的部分,随机初始化会产生巨大的发散。
Stop training the model when accuracy on the validation set decreases Or train for a long time, but always keep track of the model snapshot that worked best on val. Always a good idea to do this!
Summary:
- 在训练期间逐步降低学习率可以提高准确性,并且减少模型的过拟合。
- 在实验中,每当进展趋于稳定时就降低学习率,这是很有效的。从本质上说,这可以确保我们有效地收敛到一个适当的解,也只有这样才能通过降低学习率来减小参数的固有方差。
- 目前并没有很好的研究来对比这些不同的学习率衰减方案,所以并没有办法比较他们之间的优劣,但是深度学习的不同领域会对不同的方案有所偏好。例如,余弦式衰减在某些计算机视觉问题中很受欢迎。大规模语言模型经常使用线性衰减
- 优化之前的预热期可以防止发散。
- 优化在深度学习中有多种用途。对于同样的训练误差而言,选择不同的优化算法和学习率调度,除了最大限度地减少训练时间,可以导致测试集上不同的泛化和过拟合量。
Choosing Hyperparameters
下面两种优化方法都是基于黑箱的

第一种方法是网格搜索,我们选择一些关心的超参数集,对其中每一个超参数,我们选择一些想要评估的数值集(对数线性的方式),然后测试不同的组合
但是这需要非常多次的尝试,需要非常多的算力,而且要调整的次数是超参数数量的指数倍,故这不是一种很好的方法。
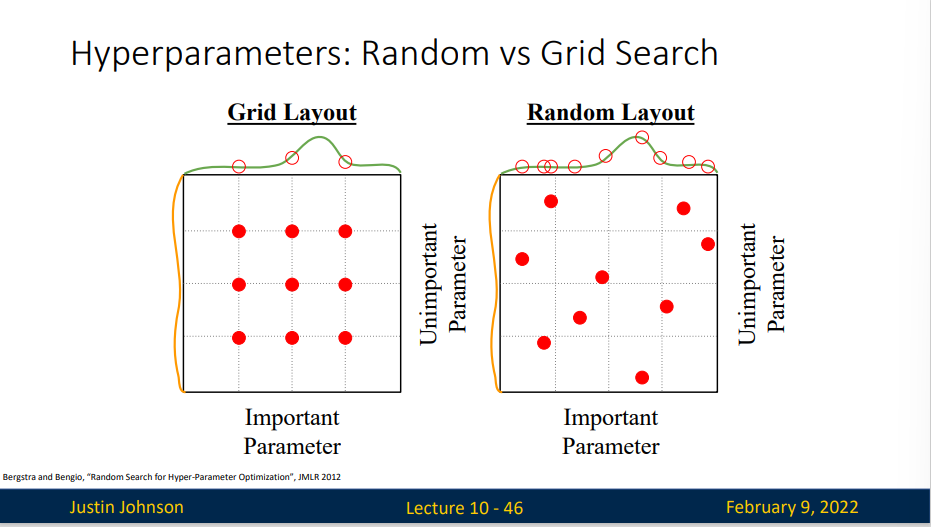
我们提出另一种办法:随机搜索。我们还是找到那个对数线性排列的范围,然后在该范围的每种参数类型里面选一个随机值来进行训练
随机搜索的效果会比网格搜索更好,这是在2012年的一篇论文中提到的,其中的想法是,如果你有很多的超参数需要调整,但是你不知道这些超参数哪一个对模型性能的影响更大(或者说哪些超参数对模型的性能影响很小)
如果我们考虑超参数对模型影响的边缘分布的话,可能会出现下面的情况
无大量GPU情况来选择超参数
Step 1 : 检查初始损失(Check initial loss)
假定已经实现了模型,那么第一步就是通过损失函数的结构来分析计算你在随机初始化的时候期望什么样的初始损失,比如说交叉熵损失,你知道它应该减去类数的对数
然后关闭权重衰减,并在初始化时检查这种损失,它只要一次迭代,它非常便宜,非常快
如果损失是错误的,那就需要去修复
Step 2 : 进行过拟合 (Overfit a small sample)
下一步是尝试过拟合你的训练数据中一个非常小批量的样本,尝试过拟合到百分百(可能需要关闭正则化,或者加上其他的方法),使得你正在处理的模型可以在非常小的训练集上达到百分百准确率(或者说找到一组超参数使得你可以完成),这些操作可以保证你的优化循环中没有任何错误,因为如果你不能拟合一小批数据,那么自然无法完成对大训练集的拟合(这个阶段会发现很多错误)
Step 3 : 找到一个可以让损失快速下降的学习率 (Find LR that makes loss go down)
如果可以做到过拟合,那就使用这个架构,现在使用所有的训练数据,你的目标是找到一个学习率,可以使得损失在你的整个训练集上开始快速下降
这个时候你只需要改变学习率就可以。你的目标是损失在前一百次左右的训练迭代中显着下降
Step 4 : 在粗网格的情况下训练1到5次 (Coarse grid, train for ~1-5 epochs)
从选择一些在步骤3中生效的学习率和权重衰减,然后训练一些小模型1到5次
Step 4 : Refined grid, train longer
从步骤4中选取最好的模型,不适用学习率衰减将它们训练更长次数
Step 6 : Look at learning curves
一些考虑情况:
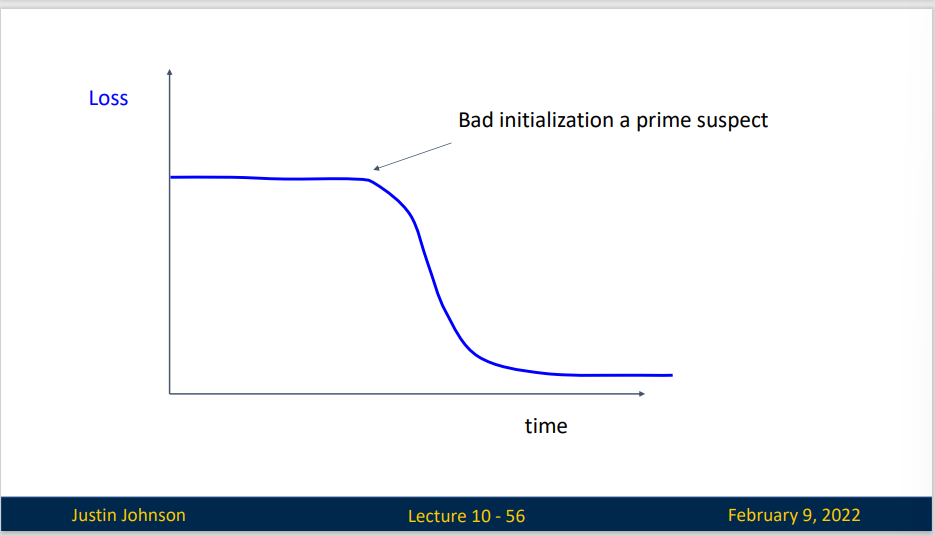
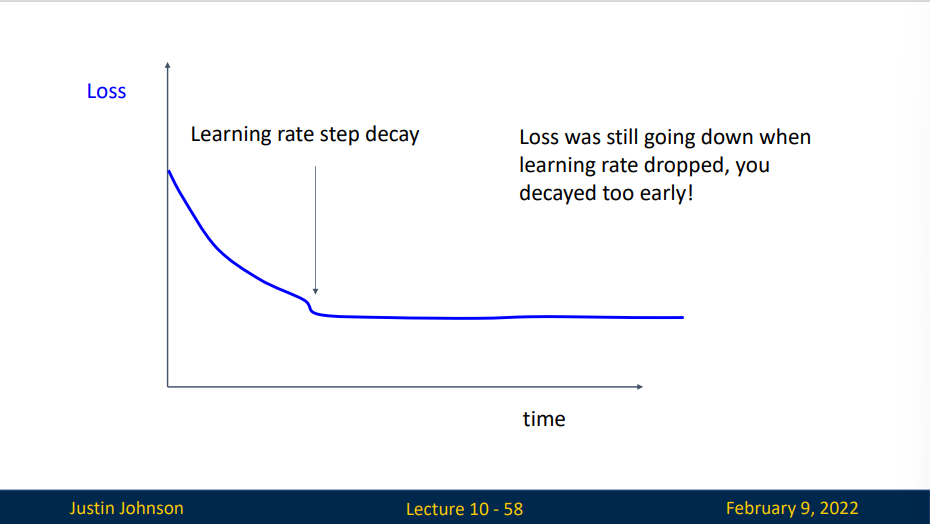
如果你的损失函数在前面训练的时候出现了一段平台期,然后出现了急剧下降,那可能意味你的初始化参数并没有选好,你应该选择一个更好的初始化参数。
如果损失函数出现了平台,那么你的学习率可能太高了,你需要衰减你的学习率
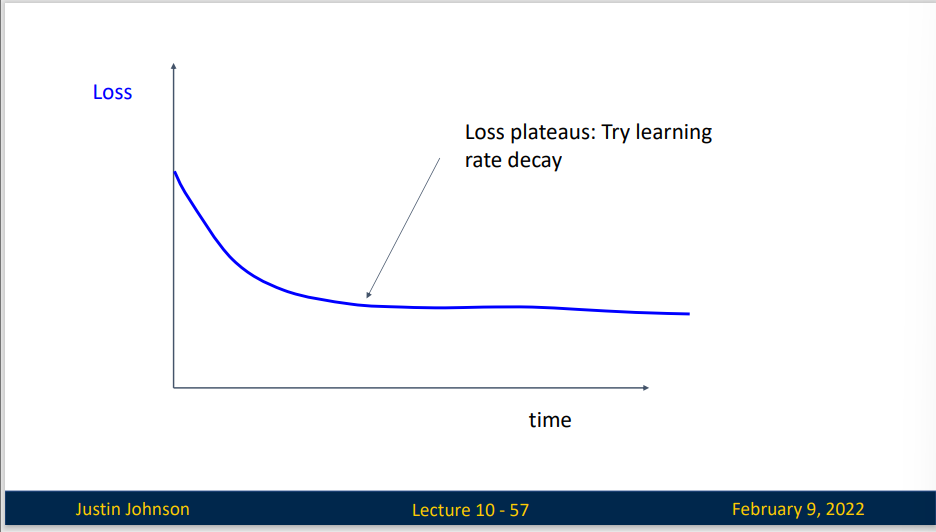
如果你过早的引入学习率衰减,损失函数会下降然后呈现一段平稳期
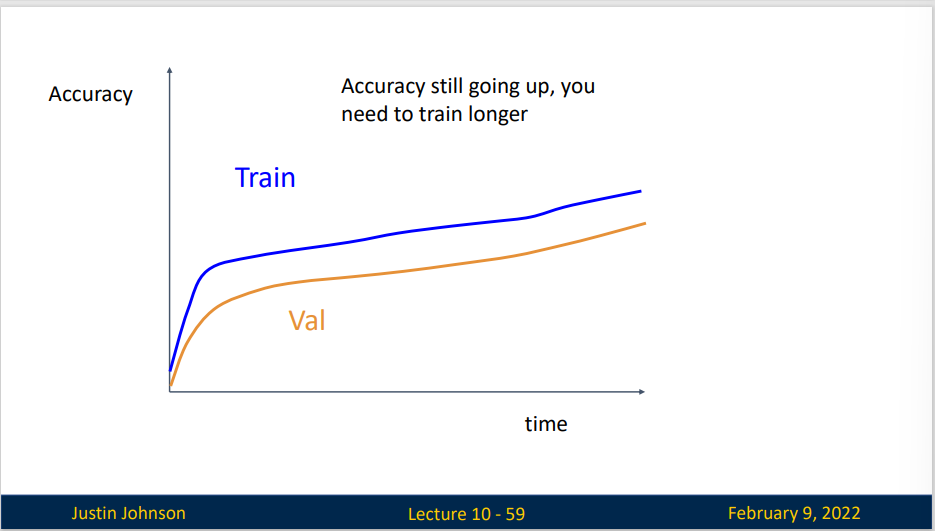
如果出现先指数增长但后面出现线性增长,这表明你的模型训练的很好。
如果你的训练集上表现特别好,但是验证集上出现了下降,这说明出现了过拟合现象,你需要增加正则化强度或收集更多数据
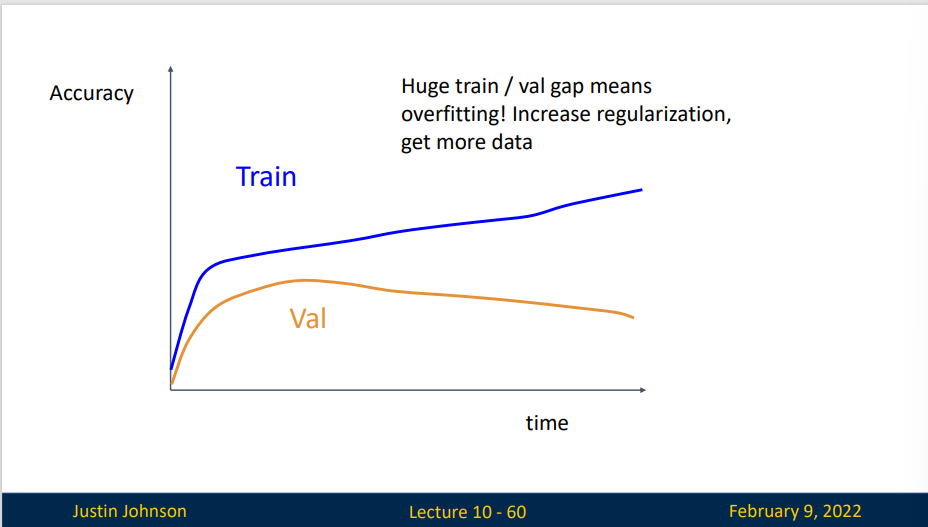
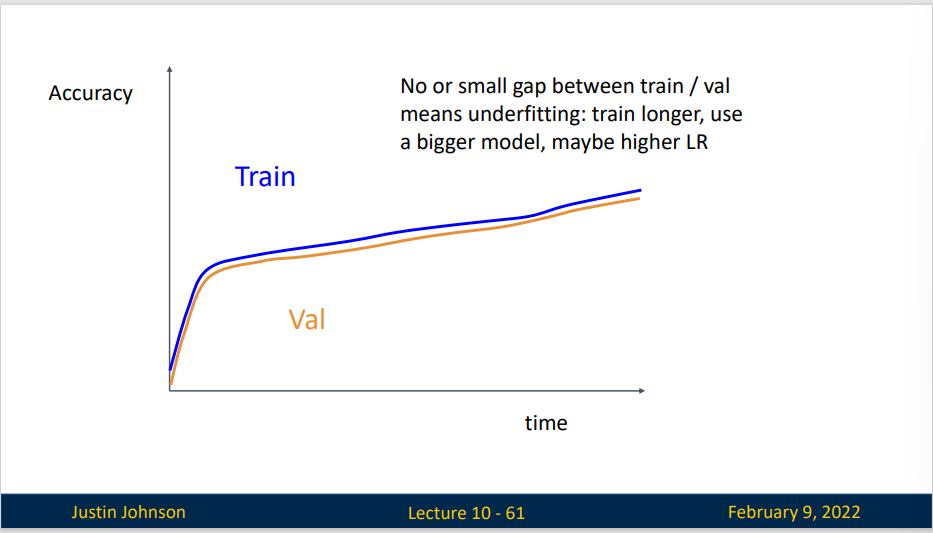
如果训练表现和验证表现非常接近,这可能并不是一个好现象,它表明你可能出现了欠拟合(这件事可能并不是一件很容易理解的事)
Step 7 : GOTO step 5
hyperparameters to play with
- Network architecture
- Learning rate, its decay schedule, update type
- Regularization (L2/Dropout strength)
Model Ensembles
Ensemble Models: What Are They and When Should You Use Them? | Built In
- Train multiple independent models
- At test time average their result
模型集成是融合多个训练好的模型,基于某种方式实现测试数据的多模型融合,这样来使得最终的结果能够“取长补短”,融合各个模型的学习能量,提高最终模型的泛化能力。模型集成方法主要应用在几个模型差异性较大,相关性较小,这样效果比较明显。
The technical challenges of building a single estimator include: - High variance: The model is very sensitive to the provided inputs for the learned features. - Low accuracy: One model (or one algorithm) to fit the entire training data might not provide you with the nuance your project requires. - Features noise and bias: The model relies heavily on too few features while making a prediction.
Tips and Tricks: - Instead of training independent models, use multiple snapshots of a sigle model during training! - Instead of using actual parameter vector, keep a moving average of the parameter vector and use that at test time (Polyak averaging)
Types of Ensemble Modeling Techniques
- Bagging
- Boosting
- Stacking
- Blending
Transfer Learning
迁移学习(Transfer learning) 属于机器学习的一种领域,它专注于存储已有问题的的解决模式,并将其利用在其他不同但相关问题上。比如说,用来识别汽车的模型也可以被用来提升识别卡车的能力。
迁移学习使得我们不用大量数据来训练新的模型,迁移学习已经成为了CV(Computer Vision)的重要部分
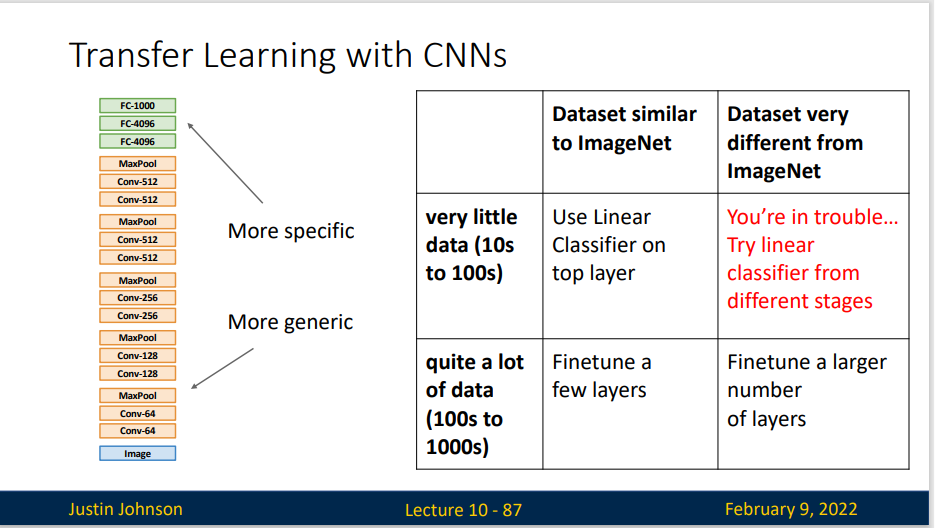
- Train on Imagenet
- Use CNN as a feature extractor : Remove last layer and freeze the left weights
- Bigger dataset: Fine-Tuning
- Continue training CNN for new task
- Train with feature extraction first before fine-tuning
- Lower the learning rate: use ~1/10 of LR used in original training
- Sometims freeze lower layers to save computation
- Continue training CNN for new task
Improvements in CNN architectures lead to improvements in many downstream tasks thanks to transfer learning!
课堂上给出的例子:

Some very recent result have questioned it
- Training from scratch can work as well as pretraing on ImageNet
- Pretraining + Finetuning beats training from scratch when dataset size is very small : Collecting more data is more effective than pretraining
Current view on transfer learning :
- Pretrain + finetune makes your training fatser, so pratically very useful
- Training from scracth works well once you have enough data
- Lots of work left to be done