CNN Architectures Ⅱ
约 6183 个字 22 张图片 预计阅读时间 41 分钟
Note
这一篇在笔记参考或19fall的PPT里是没有,他主要是介绍近几年比较高效的CNN 网络,我把论文和别人写的相关解析都贴出来啦
前情提要: CNN Architectures
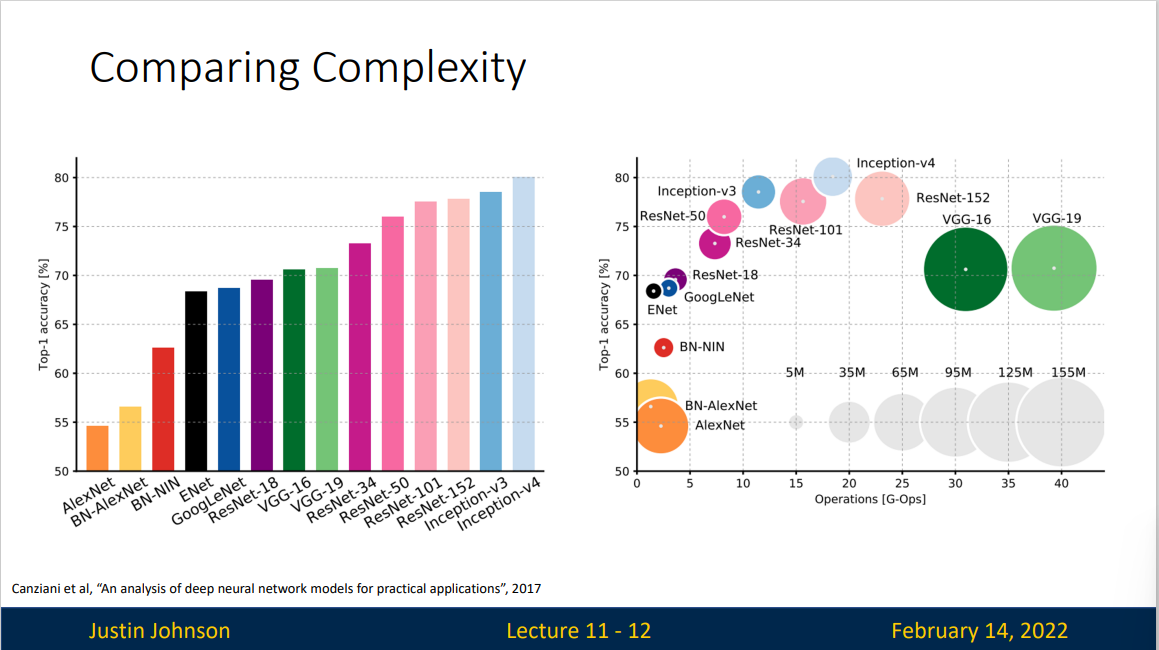
ResNet made it possible to increase accuracy with larger,deeper models
Many followup architectures emphasize efficiency: can we improbe accuracy while controlling for model "complexity"
我们给出描述一个模型的方法:
Measures of Model Complexity
- Parameters: How many learnable parameters does the model have?
- Floating Point Operations(FLOPs): How many arithmetic operations does it take to compute the forward pass of the model?
- Network Runtime : How long does a forward pass of the model take on real hardware
我们给出不同神经网络的复杂程度
Group Convolution
论文参考: 1605.06489 (arxiv.org) alexnet.pdf (stanford.edu)
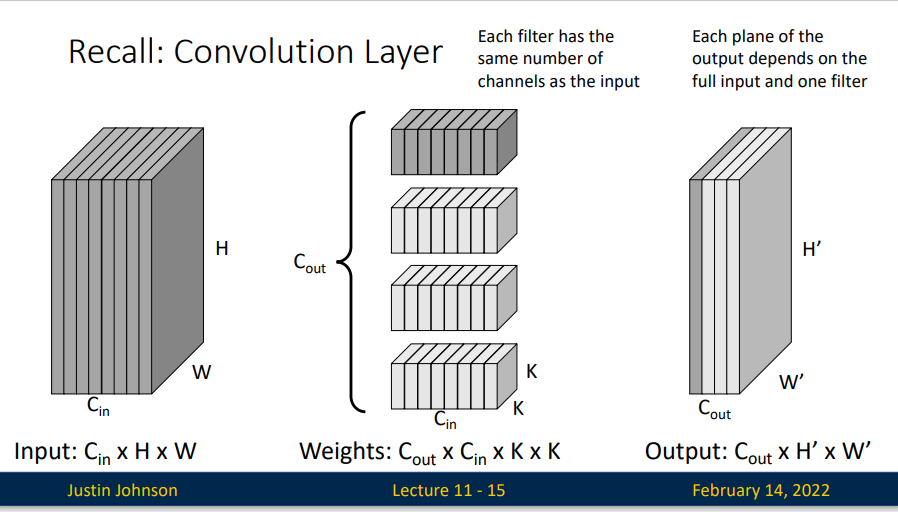
回忆我们的卷积操作,假定我们有一个尺寸为 \(C_{in} \times H \times W\) 的输入矩阵,我们有 \(C_{out}\) 个尺寸为 \(C_{in}\times K\times K\) 的卷积核,所以我们最终的到一个 \(C_{out}\times H'\times W'\) 的输出矩阵,每一层输出都依赖于输入矩阵和一个卷积核。
在AlexNet时就曾提出,由受限于当时硬件的限制,作者不得不将卷积操作拆分到两台GPU上运行,这两台GPU的参数是不共享的。 两组卷积核学习两种不同的特征,一组学习纹理,另一组学习色彩
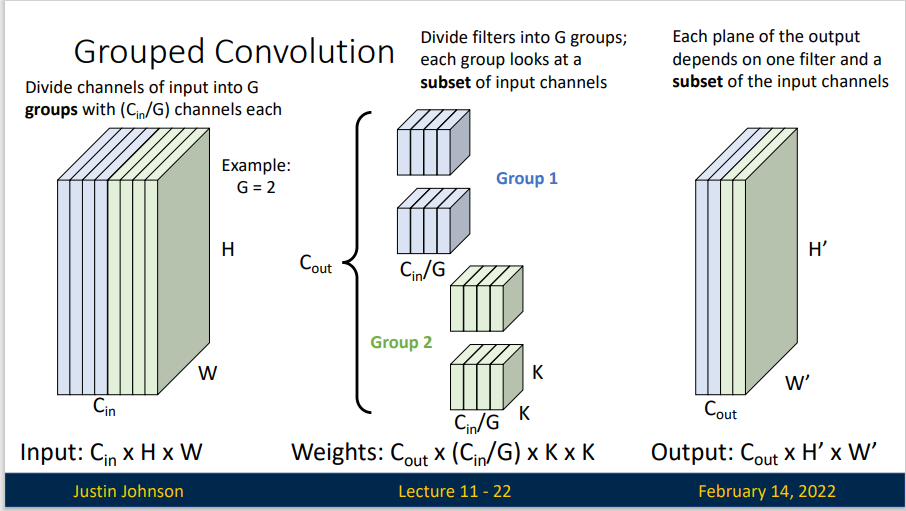
而分组卷积(Grouped Convolution)的思想是,我们将我们的输入矩阵平均分成 \(G\) 组,每一组具有 \(C_{in}/G\) 个通道。同时我们也将我们的卷积核分成 \(G\) 组,卷积核的输入通道就变成了 \(C_{in}/G\) 。对于每个组内的卷积运算,同样采用标准卷积运算的计算方式,并将其进行拼接,最终保持输出尺寸不变。
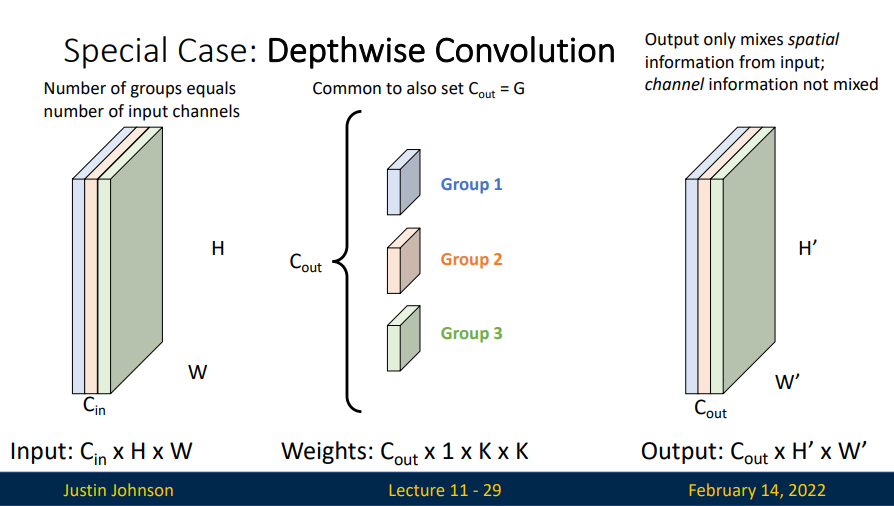
通过分组卷积,我们得到一个非常特殊的情况:深度可分离卷积(Depthwise Convolution)。 我们如果我们设置一个卷积核负责一个通道,一个通道只被一个卷积核卷积,那么我们会得到输入特征图通道数一致的输出特征图。做到深度(channel)维度不变,只改变 H 和 W。但是Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要其他方法来拓展我们的feature map。

对于分组卷积,他的浮点运算数为 \(C_{out}C_{in} K^2HW/G\) 而标准卷积的浮点运算数为 \(C_{out}C_{in} K^2HW\) 显然,使用分组卷积的有助于我们减少浮点运算
Improving ResNets: ResNeXt
论文参考:Aggregated Residual Transformations for Deep Neural Networks
笔记参考:[论文笔记] ResNeXt - 知乎 (zhihu.com)
Inception模型系列已经证明,精心设计的拓扑能够以较低的理论复杂性实现令人信服的精度。初始模型随着时间的推移而发展,但是一个重要的共同特性是拆分转换合并(split-transform-merge)策略。在Inception模块中,输入被分解为几个较低维的嵌入(按1×1卷积),由一组专用过滤器(3×3、5×5等)转换,并通过级联合并。可以证明,该体系结构的解空间是在高维嵌入中操作的单个大层(例如5×5)的解空间的严格子空间。预期Inception模块的拆分转换合并行为将接近大型和密集层的表示能力,但计算复杂度要低得多。
尽管精度很高,但是Inception模块的实现伴随着一系列复杂的因素-过滤器的数量和大小是为每个单独的转换量身定制的,并且模块是逐步定制的。尽管这些组件的精心组合产生了出色的神经网络,但是通常不清楚如何使Inception架构适应新的数据集/任务,尤其是在要设计许多因素和超参数时。(担心泛化能力)。
我们借鉴 ResNets 重复层策略,同时以简单、可拓展的方式利用层划分转换合并策略。
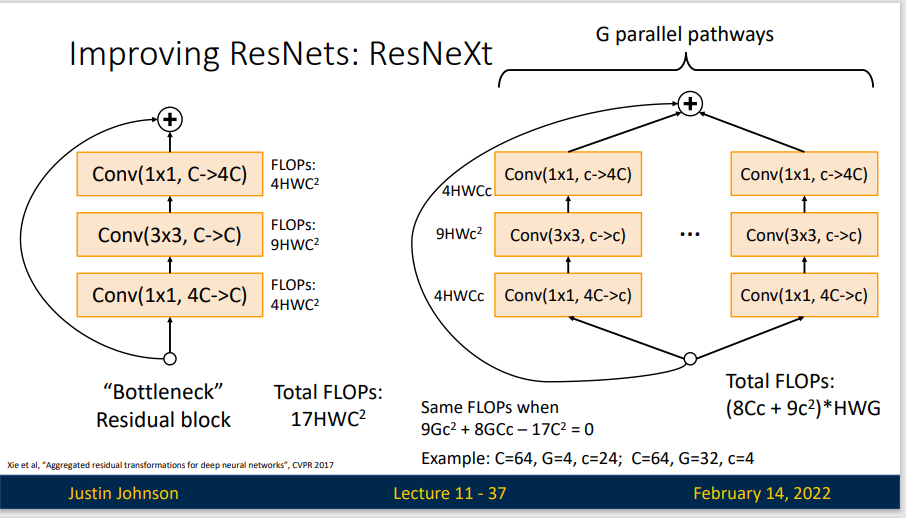
RexNeXt 增加组数保持计算性,在保持计算复杂度和模型大小的限制条件下,聚合转换也比原始的 RexNet 模块要好。
我们的方法表明,基数(转换集的大小)是一个具体的、可测量的维度,除了宽度和深度的维度外,它也是至关重要的。实验表明,增加基数比获得更深或更宽的宽度更有效地获得准确性,尤其是当深度和宽度开始为现有模型提供递减的收益时。
ResNeXt提出了一种介于普通卷积核深度可分离卷积的这种策略:分组卷积,他通过控制分组的数量(基数)来达到两种策略的平衡。分组卷积的思想是源自Inception,不同于Inception的需要人工设计每个分支,ResNeXt的每个分支的拓扑结构是相同的。最后再结合残差网络,得到的便是最终的ResNeXt。
Squeeze and Excitation Networks
论文参考:Squeeze-and-Excitation Networks
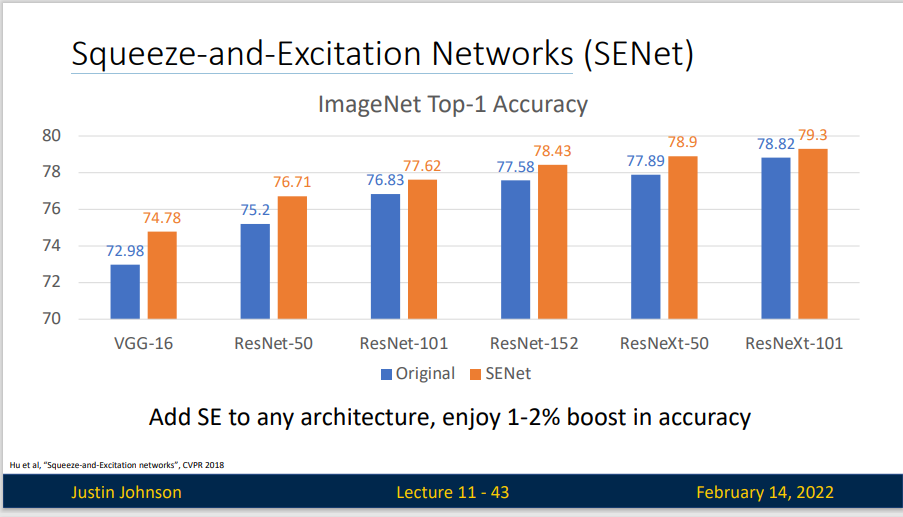
SENet的核心思想在于通过网络根据loss去学习特征权重,使得有效的feature map权重大,无效或效果小的feature map权重小的方式训练模型达到更好的结果。SE block嵌在原有的一些分类网络中不可避免地增加了一些参数和计算量,但是在效果面前还是可以接受的 。Sequeeze-and-Excitation(SE) block并不是一个完整的网络结构,而是一个子结构,可以嵌到其他分类或检测模型中。

与传统的CNN 结构相比,SENet 增加了额外3个步骤
- Squeeze 操作,顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。
- 其次是 Excitation 操作,它是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。
- 最后是一个 Reweight 的操作,将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
SENet 取得了最后一界ILSVRC的冠军
MobileNets
我们希望能够在移动设备上实现小型的神经网络,对于这一类神经网络,与其追求更大更精确的网络结构,它更希望在复杂性和准确性上取得一种平衡。
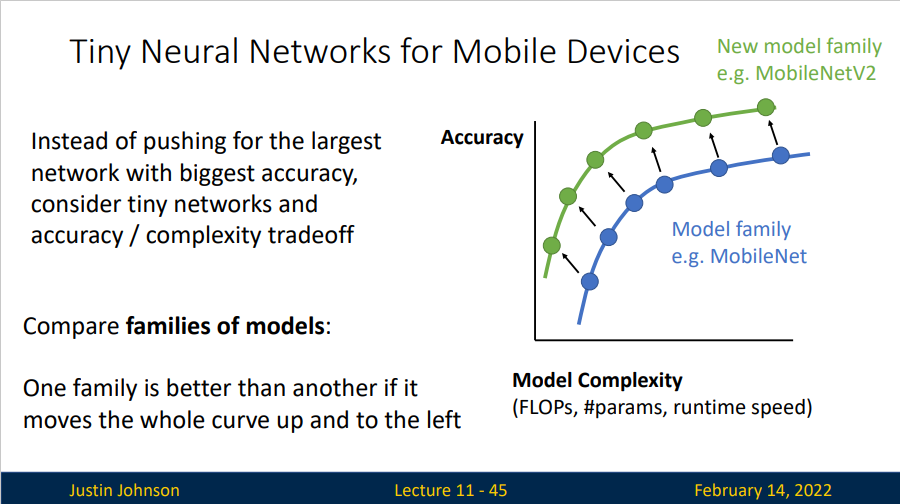
对于不同的模型类型,我们希望它的准确性复杂度曲线能够更靠左上方。
论文参考:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
笔记参考:卷积神经网络学习笔记——轻量化网络MobileNet系列(V1,V2,V3) - 战争热诚 - 博客园 (cnblogs.com)
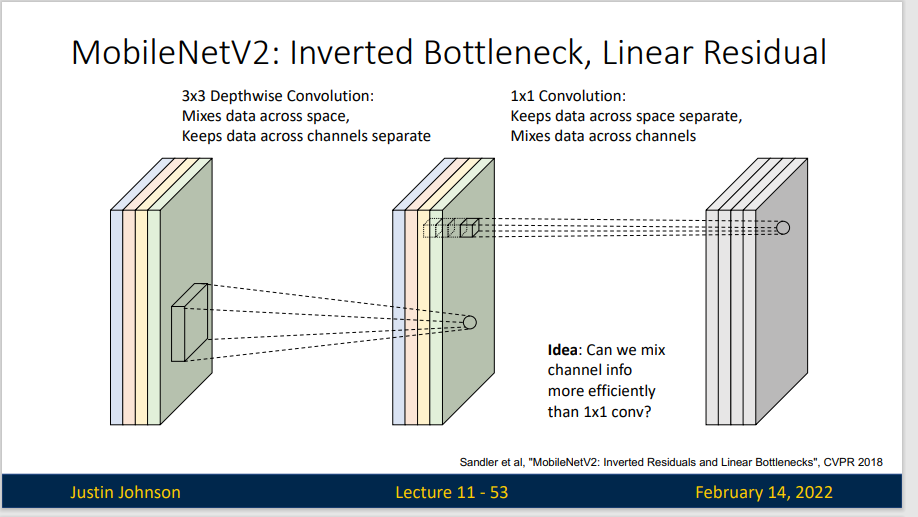
MobileNet 采用的是 Depthwise Separable Convoluntion 策略。我们知道Depthwise Convolution无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。这是时候引入了 Pointwise Convolution 来拓展feature map 上的信息。
Pointwise Convolution 也称逐点卷积,实际上就是 1*1 卷积,主要作用就是对feature map 进行升维和降维。
深度可分离卷积使我们能够用更少的参数、更少的运算得到相近的效果。
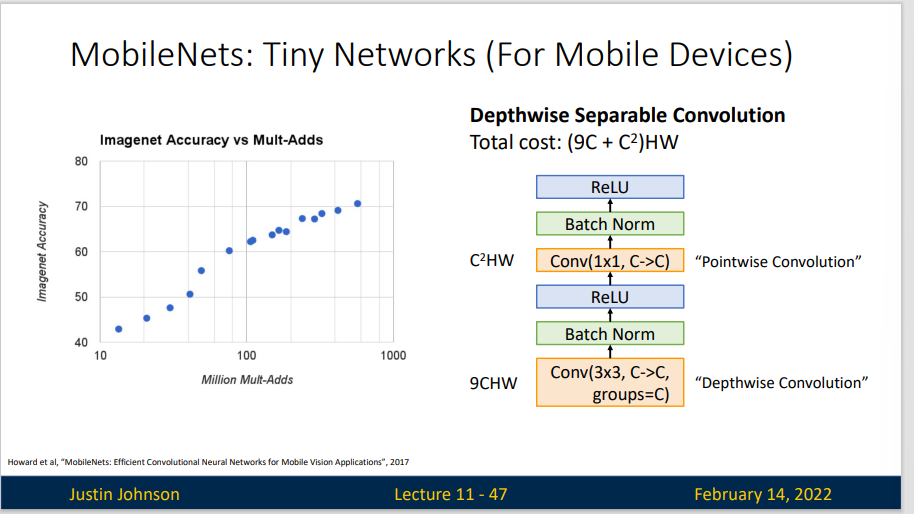
MobileNet V1是一种基于流水线结构,使用深度可分离卷积构建的轻量级神经网络,并通过两个超参数的引入使得开发人员可以基于自己的应用和资源限制选择合适的模型。
从概念上来说,MobileNet V1正试图实现两个基本目标,以构建移动第一计算视觉模型:1,较小的模型,参数数量更少;2,较小的复杂度,运算中乘法和加法更少。遵循这些原则,MobileNet V1 是一个小型,低延迟,低功耗的参数化模型,可以满足各种用例的资源约束。它们可以用于实现:分类,检测,嵌入和分割等功能。
MobileNet V2 给出的两个超参数:
- 宽度因子 \(\alpha\) (Width Mutiplier)在每一层对网络的输入输出通道数进行缩减
- 分辨率因子 \(\rho\) (resolution multiplier) 用于控制输入和内部层表示
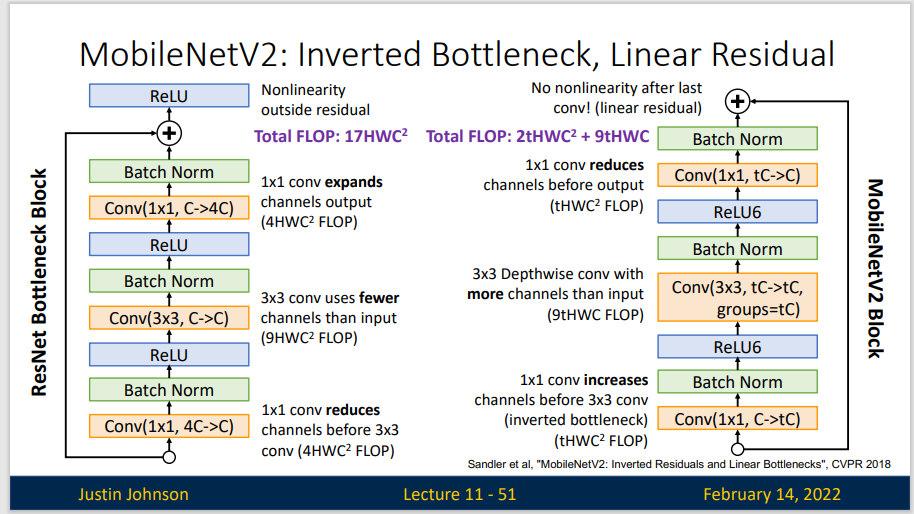
MobileNet V2基于MobileNet V1的一些思想,并结合新的思想来优化。从架构上来看,MobileNet V2为架构增添了两个新模块:1,引入了层与层之间的线性瓶颈;2,瓶颈之间的快捷连接。
MobileNet V2之中的核心思想是,瓶颈对模型的中间输入和输出进行编码,而内层则用于封装模型从较低级别概念(如:像素等)转换到较高级别描述符(如:图像类别等)的能力。最后,与传统的剩余连接一样,快捷方式能够实现更快地训练速度和更高的准确率。
Inverted Residuals: 输入首先经过1*1的卷积进行通道扩张,然后使用3*3的depthwise卷积,最后使用1*1的pointwise卷积将通道数压缩回去。整个过程是“扩张-卷积-压缩”。为什么这么做呢?因为depthwise卷积不能改变通道数,因此特征提取受限于输入的通道数,所以将通道数先提升上去。
Linear Bottleneck: V2在DW卷积之前新加了一个PW卷积,这么做的原因是因为DW卷积由于本身的计算特性决定它自己没有改变通道数的能力,上一层给他多少通道,他就只能输出多少通道。所以如果上一层的通道数本身很少的话,DW也只能很委屈的低维空间提取特征,因此效果不是很好,现在V2为了改善这个问题,给每个 DW 之前都配备了一个PW,专门用来升维,定义升维系数为 t=6,这样不管输入通道数Cin 是多是少,经过第一个 PW 升维之后,DW都是在相对的更高维(t*Cin)是多是少,经过第一个 PW升维之后,DW 都是在相对的更高维(t*Cin)进行辛勤工作的。而且V2去掉了第二个PW的激活函数,论文作者称其为 Linear Bottleneck。这么做的渊源,是因为作者认为激活函数在高维空间能够有效的增加非线性,而在低维空间时则会破坏特征,不如线性的效果好。
ShuffleNet
论文:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
笔记参考:【深度学习经典网络架构—9】:ShuffleNet系列(V1、V2)-CSDN博客
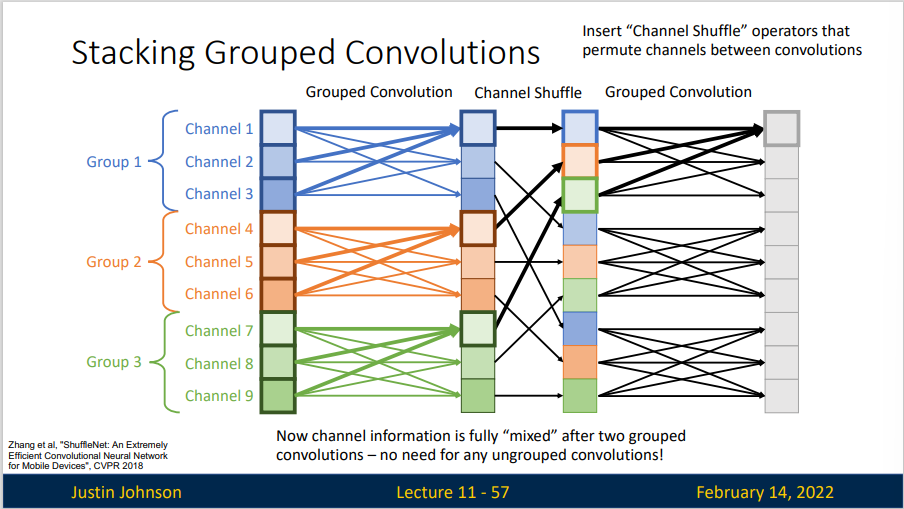
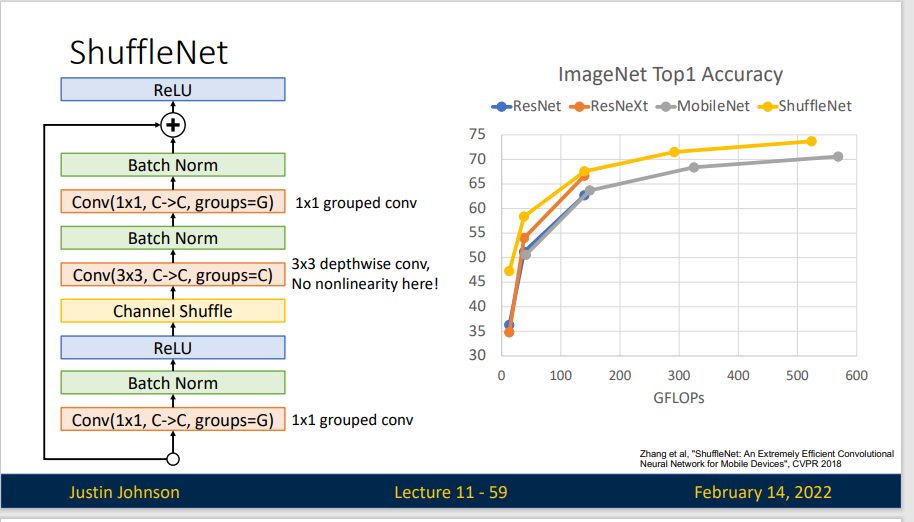
ShuffleNet 也是一种轻量级的神经网络,在ShuffleNet中,作者使用了两个操作,分别是逐点组卷积(pointwise group convolution)和通道混洗(channel shuffle)
在小型网络中,昂贵的点卷积会使得有限的通道之间充满了约束,显著的损失精度。为了解决这个问题,通常会使用像 group convolution 一样的通道稀疏连接,确保每个卷积操作仅在对应的输入通道组上。但是多个组卷积堆叠会产生副作用:某个通道输出仅从一小部分输入通道中导出,这样会降低通道组间的信息流动能力,降低了信息表达能力。
所以我们在两个 Grouped Convolution 之间插入通道混洗,将每个组中的特征图均匀混合。
可以看出根据这种思路设计出来的ShuffleNet效果非常好。
Neural Architecture Search (NAS)
笔记参考:神经架构搜索(NAS)简要介绍 - 知乎 (zhihu.com)
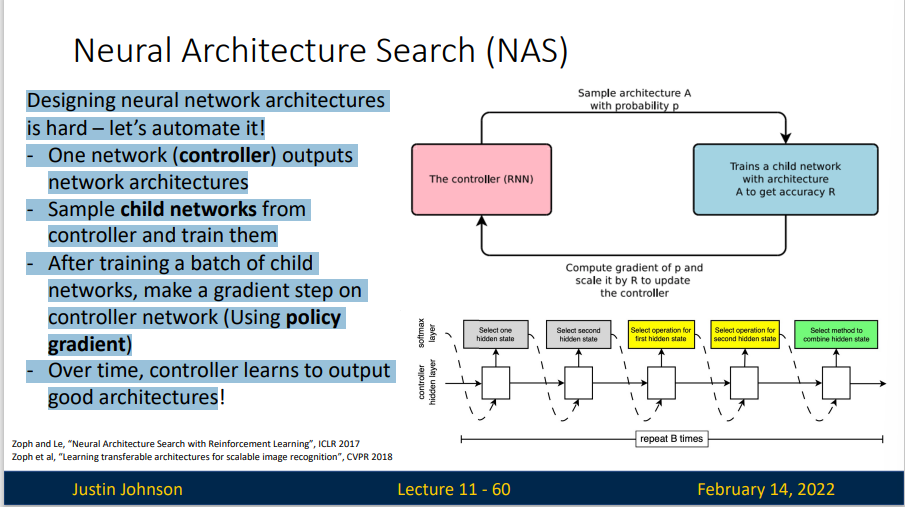
Designing neural network architectures is hard —— let’s automate it!
- One network (controller) outputs network architectures
- Sample child networks from controller and train them
- After training a batch of child networks, make a gradient step on controller network (Using policy gradient)
- Over time, controller learns to output good architectures
NAS的意义在于解决深度学习模型的调参问题,是结合了优化和机器学习的交叉研究。在深度学习之前,传统的机器学习模型也会遇到模型的调参问题,因为浅层模型结构相对简单,因此多数研究都将模型的结构统一为超参数来进行搜索,比如三层神经网络中隐层神经元的个数。优化这些超参数的方法主要是黑箱优化方法,比如分别为进化优化,贝叶斯优化和强化学习等
但是在模型规模扩大之后,超参数增多,这给优化问题带来了新的挑战。传统的方法遇到的问题主要有:结构编码方式无法代表复杂的网络结构搜索空间,编码空间过大导致这些搜索算法无法收敛,深度学习模型训练时间太长导致黑箱优化方法的计算效率降低等
NAS的主要研究问题可以总体上分为3个部分:构建搜索空间,优化算法以及模型评估。
NAS的搜索空间被认为是一个神经网络搜索空间的一个带有约束子空间。NAS的搜索空间直接影响的优化的难度,NAS的研究重点之一就在于如何构造一个高效的搜索空间。由于深度学习的结构比较复杂,层次化的结构已经被证实十分有效,因此一开始的搜索空间的构造仍然以链式结构为主。链式搜索空间(chain-structured search space)首先被提出,主要的思想是将不同的操作单元组合在一起,这样的搜索空间也被称为全局搜索空间(Global search space)。Global search spaces 限制了神经网络的整体架构和链接方向,NAS需要调整的知识每一层所做的操作和对应的参数。每一层的操作有不同的选择,例如可以是卷积,池化,线性变换等。Global search spaces 相对来讲比较灵活,可以允许神经网络变换出各种结构(只要设计时允许跨层连接或者层间连接),但是问题也很明显,那就是巨大的搜索空间使得很多优化算法都没办法快速解决它。Global search spaces 带来了十分昂贵的计算代价。
为了尽量减少计算消耗,不得不想办法减小搜索空间。后来主流的研究方法集中在了模块化网络结构并进行拼装(cell-based search space),这个思想主要来源于很多人工设计的结构具有很好效果,这样就可以整块的将网络结构进行组合,每一块具备一项功能,由NAS来决定每一块的位置和参数,这样一来搜索空间就降低了很多。这些cell都是一个小型的有向无环图(DAG),用来抽取和传递特征。
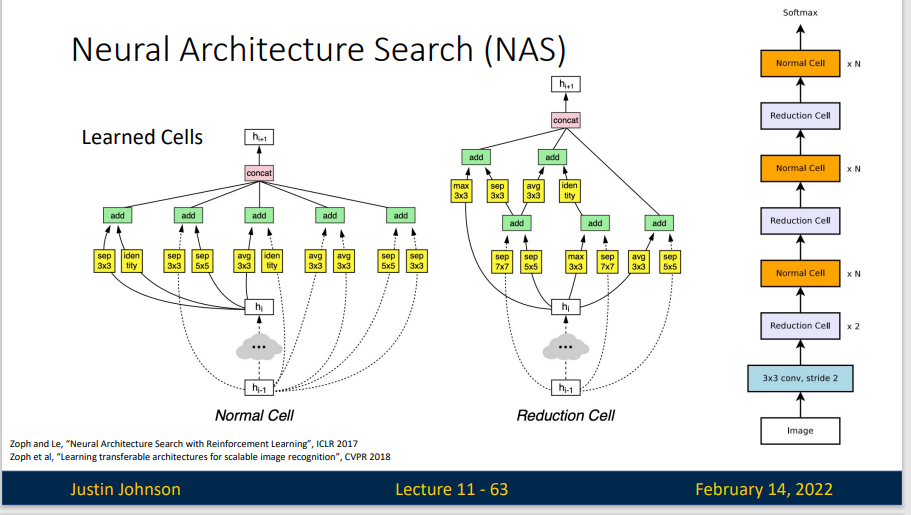
尽管NAS非常高效,但是 NAS 有一个问题,他的代价太高了。你需要训练大量的cell,迭代一次网络都需要从头开始训练,在训练每个模块参数上又会花费很多时间。
Original NAS paper: Each update to the controller requires training 800 child models for 50 epochs on CIFAR10; Total of 12,800 child models are trained。
EfficientNets
论文参考:EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
笔记参考:卷积神经网络(十一)EfficientNet v1 - 知乎 (zhihu.com)
模型扩展(Model Scaling)指的是增加机器学习模型的规模、容量或性能,以处理更复杂的任务、更大的数据集或提高精度。模型扩展通常涉及到对架构、参数或训练数据的调整。在深度学习和人工智能领域,模型扩展是提高模型性能的关键因素,但也带来了计算资源需求、过拟合和部署复杂性等挑战。
下图给出了一些模型扩展的方法
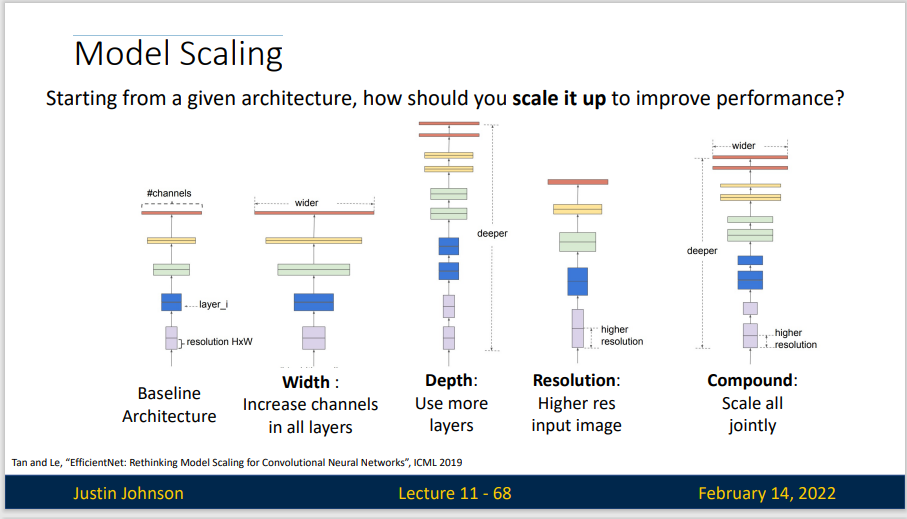
EfficientNets 正是用了复合缩放(Compound Model Scaling)的方法来提高模型精度和效率,可用于扩展现有的模型。
对于一个CNN网络来说,影响模型参数大小和速度的主要有三个方面:depth,width,resolution (image size)。depth 指的是模型的深度,即网络的层数,网络越深,感受野越大,提取的特征语义越强;width 指的是网络特征维度大小(channels),特征维度越大,模型的表征能力越强;resolution 指的是网络的输入图像大小,即HxW,输入图像分辨率越大,越有利于提取更细粒度特征。depth 和 width 影响模型参数大小和速度,但是 resolution 只影响模型速度(分辨率越大,计算量越大)。
- 增加网络的 depth 能够得到更加丰富、复杂的高级语义特征,并且能很好的应用到其他任务中去。但是网络的深度过深会面临梯度消失,训练困难等问题。
- 增加网络的 width 能够获得更高细粒度的特征,并且也更容易训练。但是对于宽度很大,深度较浅的网络往往很难学习到更深层次的特征。例如我就只有一个 3×3 的卷积,但是输出通道为 10000,也没办法得到更为抽象的高级语义。
- 增加输入网络的图像分辨率能够潜在获得更高细粒度的特征模版,图像分辨率越高能看到的细节就越多,能提升分辨能力。但是对于非常高的输入分辨率,准确率的增益也会减少。且大分辨率图像会增加网络的计算量(注意不是参数量)。
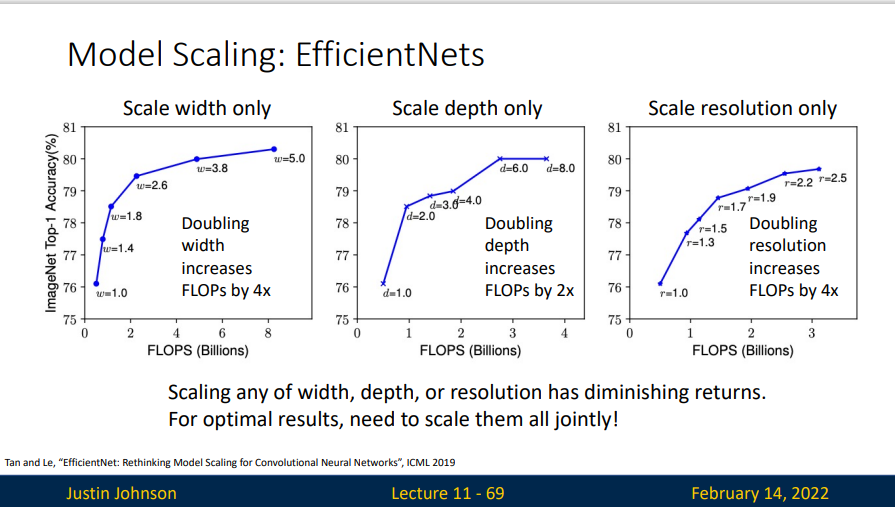
当理论计算量相同时,同时增加这三者,要比单独增加其中一个得到的效果更好。
- Use NAS to get initial EfficientNet-B0 architecture; uses depthwise conv, inverted bottlenecks, and SE
- Find optimal scaling factors \(\alpha\) for depth, \(\beta\) for width, \(\gamma\) for resolution with \(\alpha,\beta,\gamma\) ≥ 1 and \(\alpha\beta^2\gamma^2 ≈ 2\) via grid search on scaling up initial architecture; found \(\alpha=1.2,\beta =1.1\gamma =1.15\)
- Scale initial architecture to arbitrary FLOPs: scaling by \(\alpha^\phi,\beta^\phi,\gamma^\phi\) will increase FLOPs by a factor of \(\phi\)≈ 2
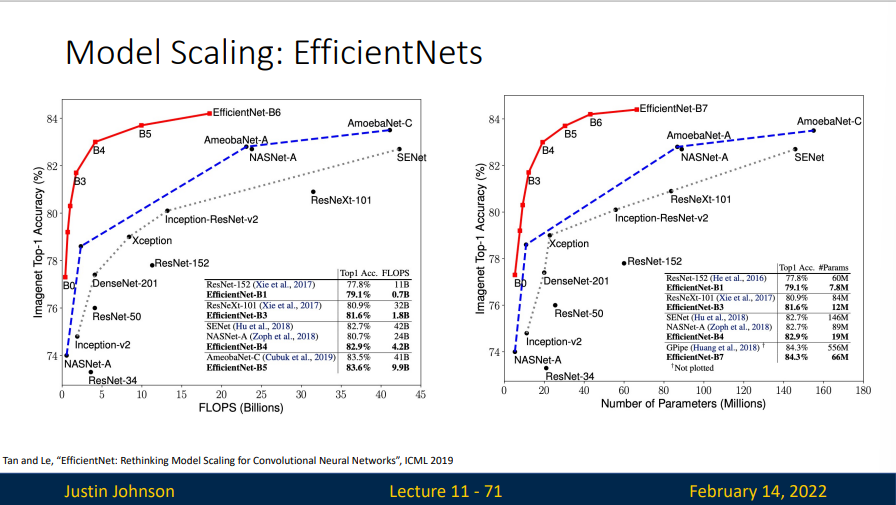
可以看出这种方法非常有效。
Big problem: Real-world runtime does not correlate well with FLOPs!
- Runtime depends on the device (mobile CPU, server CPU, GPU, TPU); A model which is fast on one device may be slow on another
- Depthwise convolutions are efficient on mobile, but not on GPU / TPU - they become memory-bound
- The “naïve” FLOP counting we have done for convolutions can be incorrect – alternate conv algorithms can reduce FLOPs in some settings (FFT for large kernels, Winograd for 3x3 conv)
- EfficientNet was designed to minimize FLOPs, not actual runtime – so it is surprisingly slow!
NFNets
论文参考: High-Performance Large-Scale Image Recognition Without Normalization
- Batch Normalization has good properties:
- Makes it easy to train deep networks >= 10 layers
- Makes learning rates, initialization less critical
- Adds regularization
- ”Free” at inference: can be merged into linear layers
- But also has bad properties:
- Doesn’t work with small minibatches
- Different behavior at train and test
- Slow at training time
事实上 NFNets 是一种没有批量归一化的 ResNets 网络
NFNets 网络建立在 Normalizer-Free ResNet (NF-ResNet) 上,这是一类可以在没有归一化层的情况下,被训练成具有训练和测试准确率的预激活 ResNet。
在早期的 ResNet 网络上,方差是随着残差块逐渐增长的,于是为了解决这个问题,提出了一个 Re-parameterize block:
其中, \(\alpha\) 是超参数,\(\beta_l = \sqrt{Var(x_l)}\) ,在训练过程中都是常数。
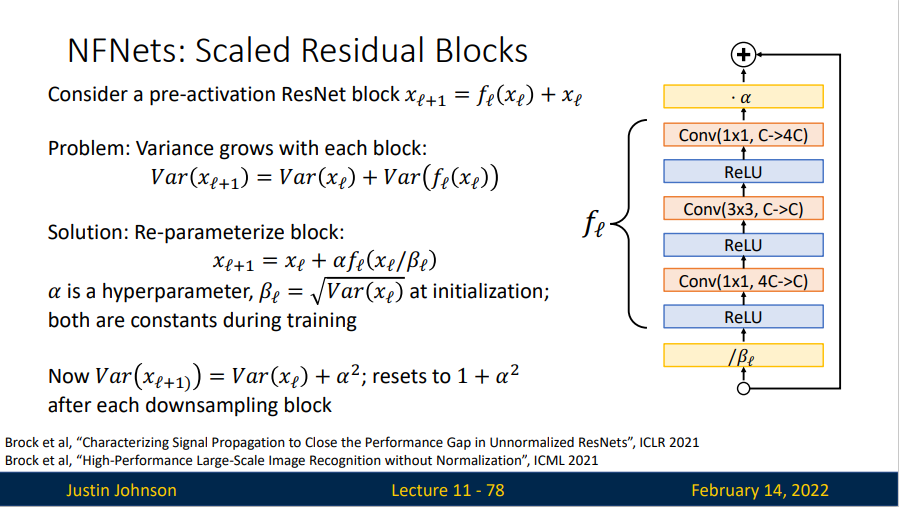
Rather than normalizing activations during training, instead normalize weights
Learn weights \(W\) but convolve with weights \(\widehat{W}\) where
\(W_i\) is a single conv filter, \(N = K^2C_{in}\) is the "fan- in" of the kernel \(\gamma\) is a constant that depends on the nonlinearity
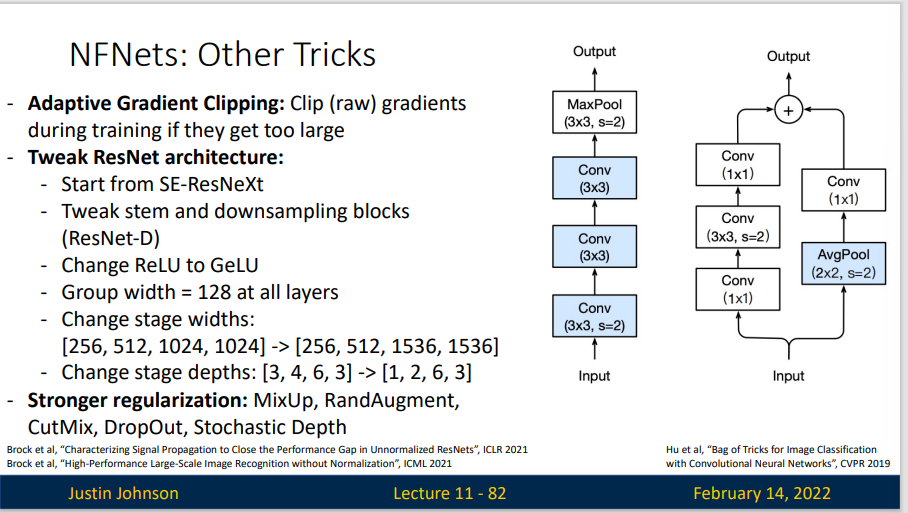
为了将 NF-ResNet 扩展到更大的批规模,研究者探索了一系列梯度裁剪策略。梯度裁剪通常被用于语言建模中以稳定训练。近来一些研究表明:与梯度下降相比,梯度裁剪允许以更高的学习率进行训练,从而加快收敛速度。这对于条件较差的 loss landscape 或大批量训练尤为重要。因为在这些情况下,最佳学习率受到最大稳定学习率的限制。因此该研究假设梯度裁剪应该有助于将 NF-ResNet 有效地扩展到大批量设置。
还有一些技巧:
RegNets
论文参考:egNet: Self-Regulated Network for Image Classification
详解何恺明团队最新作品:源于Facebook AI的RegNet | 机器之心
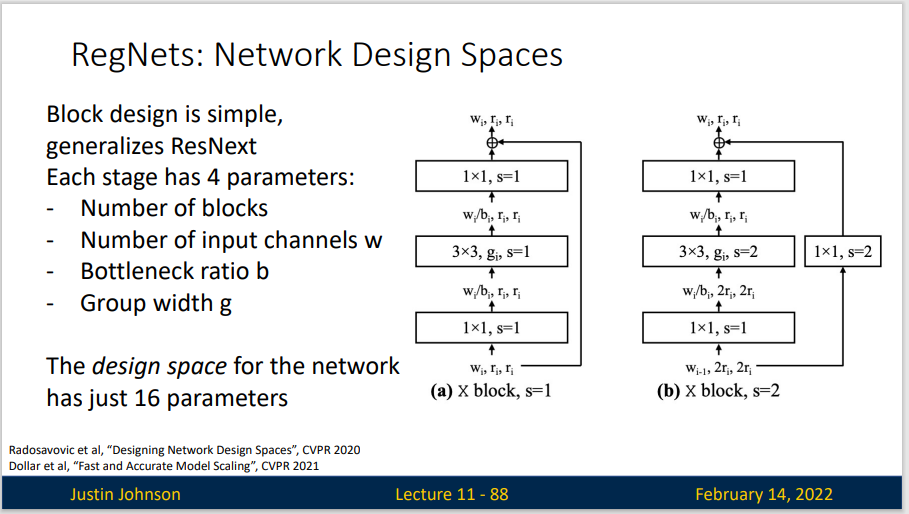
Network Design Spaces : 在设计空间中对模型进行采样,从而产生模型分布,并可以使用经典统计学中的工具来分析设计空间。
在这个设计空间中,网络的每一层的参数都受到约束,使得模型能够在给定计算预算下达到最优性能。RegNet的设计空间简化了结构选择,不像传统网络那样需要大量的手工设计。
RegNet在结构上采用了均匀分布的特征块,而不是使用很多种不同的特征层。它通过调整每层的宽度和深度来控制模型的复杂度,使模型在不同的计算预算下都能有效工作。每层特征的宽度和分布遵循特定的规律,确保特征提取的一致性。
RegNet的架构设计是通过以下几个关键参数控制的:
- Stage数:RegNet将网络分成若干个stage(阶段),每个stage对应一个特征块。
- 每层的通道宽度(Width):每层卷积的通道数是动态设定的。
- 卷积层的深度(Depth):每个特征块中卷积层的深度随stage增加而增加。
- 特征增量(W0, W_a, W_m):RegNet使用一组特定的参数(如初始宽度
W0,增长率W_a和宽度多项因子W_m)来控制每层的通道数变化,从而生成一个“宽度序列”。
Use results to refine the design space: Reduce degrees of freedom from 16 to bias toward better-performing architectures:
- Share bottleneck ratio across all stages (16 -> 13 params) 减少瓶颈比率多样性,将所有阶段的瓶颈比例统一设置为相同的值,这样就减少了参数数量,从16个到13个,简化模型设计提高效率
- Share group width across all stages (13 -> 10 params) 将所有阶段的组宽度统一为相同的值,将参数数量从13个减少到10个,是模型更加简洁
- Force width, blocks per stage to increase linearly across stages 让每个阶段的宽度和块数线性递增,使模型结构更加规则化,提高模型扩展性,确保网络能够逐步学习更复杂的特征。
最终设计空间中仅保留了6个关键参数,在保证模型高效性的同时,也让其在计算资源和性能之间实现了良好平衡
- 网络深度 (d):定义网络的总体深度。
- 瓶颈比率 (b):控制瓶颈块的压缩比率,现在在所有阶段中共享。
- 组宽度 (g):定义组卷积的宽度,同样在所有阶段中共享。
- 初始宽度 (\(w_0\)):第一个阶段的起始宽度(通道数)。
- 宽度增长率 (\(w_a\)):控制每个阶段的宽度线性增加的速率。
- 每阶段的块数增长 (\(w_m\)):控制每个阶段块数线性增加的速率。
Note
还没整完,会再加点
Summary
- Early work (AlexNet -> VGG -> ResNet): bigger networks work better
- New focus on efficiency: Improve accuracy, control for network complexity
- Grouped and Depthwise Convolution appear in many modern architectures
- Squeeze-and-Excite adds accuracy boost to just about any architecture while only adding a tiny amount of FLOPs and runtime
- Tiny networks for mobile devices (MobileNet, ShuffleNet)
- Neural Architecture Search (NAS) promised to automate architecture design
- More recent work has moved towards careful improvements to ResNet-like architectures
- ResNet and ResNeXt are still surprisingly strong and popular architectures!
- RegNet seems like a promising and efficient architecture to us