Image Segmentation
约 5427 个字 24 张图片 预计阅读时间 36 分钟
Semantic Segmentation
语义分割(Semantic Segmentation) 就是我们对图像中的每个像素打标签,比如说下图中的这只猫,我们希望对属于猫这个对象的每个像素都打上相应的标签。

当然,在语义分割中,并不会区分不同的对象,只是负责给对象打类别标签,也就是说,如果有两个紧邻的同一个类别的对象,那么会打上同一种标签(比如说上图的奶牛),不会区分不同的实例。
一个简单的方法就是使用滑动窗口,不断预测某一个小区域的类别,然后给予相应的标签。

这种方法是极为低效的,因为需要大量重复的计算,并且没有共享特征。
Fully Convolutional Network
我们使用一种名为 全连接卷积网络(Fully Convolutional Network, FCN) 的网络架构来实现语义分割任务,这是一个没有全连接层和全局池化层的网络,它只有一堆卷积层,输出与输入都有同样的二维形状(或者说输出形状由输入形状决定),输出是每个图像的分类分数,或者说具有与类别数一样的通道数的三维张量,然后使用最大化函数就可以得到一个我们想要的语义分割图。
损失函数是每个像素的交叉熵损失。
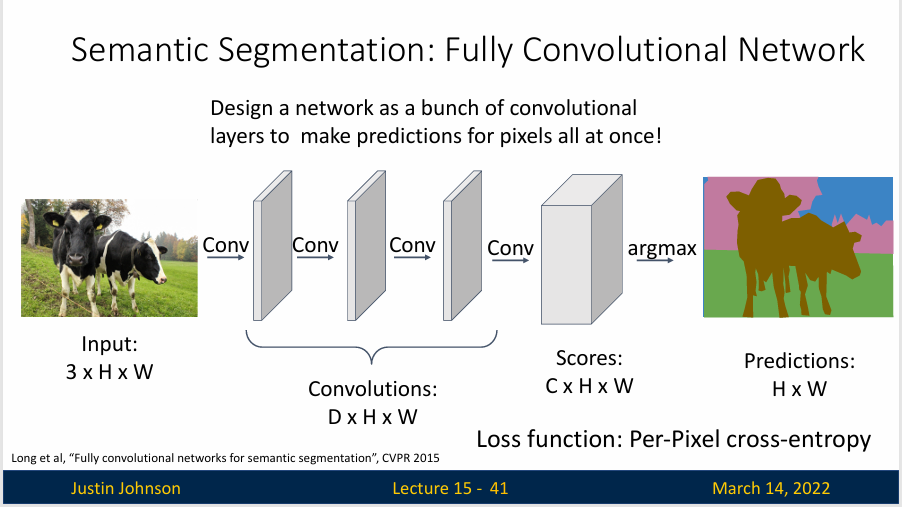
但是出现了一个问题,多层卷积会导致感受野也会逐渐增加,比如说两个3x3卷积叠在一起,那么第二层的输出实际上就是查看5x5的区域,每多一层,感受野大小就会加二,这虽然意味着网络能捕捉更广泛的上下文信息,但也意味着网络需要处理跟多的信息,极大增加了计算的复杂度。同时感受野过大也会导致网络在处理细节信息时不够精确,尤其时在图像的边缘区域,过大的感受野也可能导致网络在训练时难以学习到局部特征。
同时,另一个问题也出现了:在高分辨率图像上进行卷积操作时非常昂贵的,因为卷积操作的计算量和图像的分辨率成正比,这意味着高分辨率图像上进行卷积操作需要更多的计算资源和时间。

实际上,人们会使用上采样和下采样的架构来完成语义分割.
Downsampling and Upsampling
下采样(Downsampling):下采样是一种降低数据的分辨率或者复杂度的处理方式。在图像处理中,下采样通常是指减少图像的像素数量,使图像变得更小、更模糊。在深度学习中,下采样通常通过使用卷积层(特别是步长大于1的卷积层)或池化层(如最大池化或平均池化)来实现。通过下采样,我们可以减少计算的复杂度,同时提取出图像的高层次(也就是更抽象的)特征。然而,下采样的过程会丢失一些细节信息,这对于需要精确像素级别预测的语义分割任务来说,可能是一个问题。
上采样(Upsampling):上采样是一种增加数据分辨率或者复杂度的处理方式。在图像处理中,上采样通常指增加图像的像素数量,使图像变得更大、更清晰。在深度学习中,上采样通常通过使用转置卷积(也叫反卷积)或者插值(如最近邻插值或双线性插值)来实现。上采样的目标是恢复下采样过程中丢失的细节信息,从而使我们可以在高分辨率的输出上进行预测。这对于语义分割任务来说,是非常重要的。
在网络开始的时候进行下采样,这样就可以提取很多特征,就类似于图像分类中一样,我们甚至可以使用池化方式去进行下采样
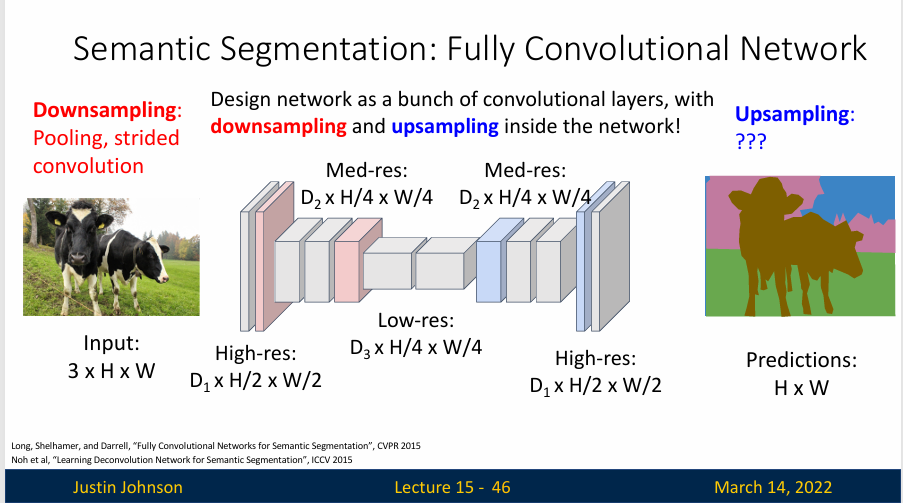
上采样可能是一种与池化操作相反的过程,或者可以称为反池化(Unpooling)
比如说我们输入一个2x2大小的矩阵,上采样就可以实现一个空间上两倍大小的输出,通道数不变
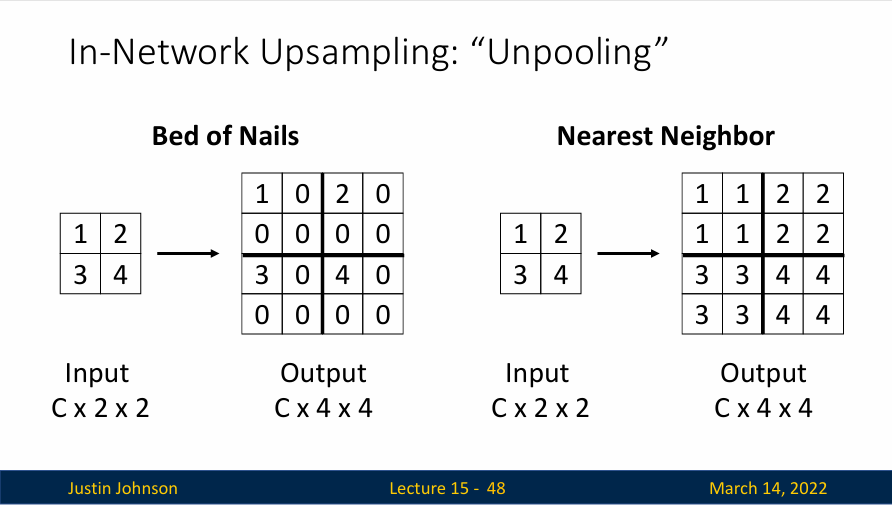
钉床(Bed of Nails,也可译为床钉):这种方法的名字来源于它的工作原理与形状。"Bed of Nails"是一种上采样策略,其工作原理类似于在下采样时丢失的位置放置"钉子"(即非零值),然后通过插值或其他方法在其他位置生成值,从而恢复原始的分辨率。在这里,我们是将原特征向量复制到每个对应区域的左上角,然后其他办法用零值填充。当然这不是一个很好的方法,所以人们通常使用另一种方法。
最近邻反池化(Nearest Neighbor):最近邻上采样方法的基本思想是:对于每一个在上采样后的新的像素位置,选取最近的原始像素值作为其值。因为它直接使用最近的像素值,所以这种方法相对简单快速,但可能会在图像中引入一些锯齿状的效果(因为它不会像一些其他上采样方法那样进行平滑处理)。
在实践中,最近邻上采样常常被用在一些需要快速但不需要过分关注图像质量的场景中。在深度学习的语义分割任务中,尤其是在进行分辨率恢复(即上采样操作)的时候,最近邻上采样也是一个常见的选择。
双线性插值(Bilinear Interpolation):在图像上采样中,双线性插值的操作可以这样理解:对于目标图像中的每一个像素,先在水平方向进行线性插值,然后在垂直方向进行线性插值,得到最终的像素值。
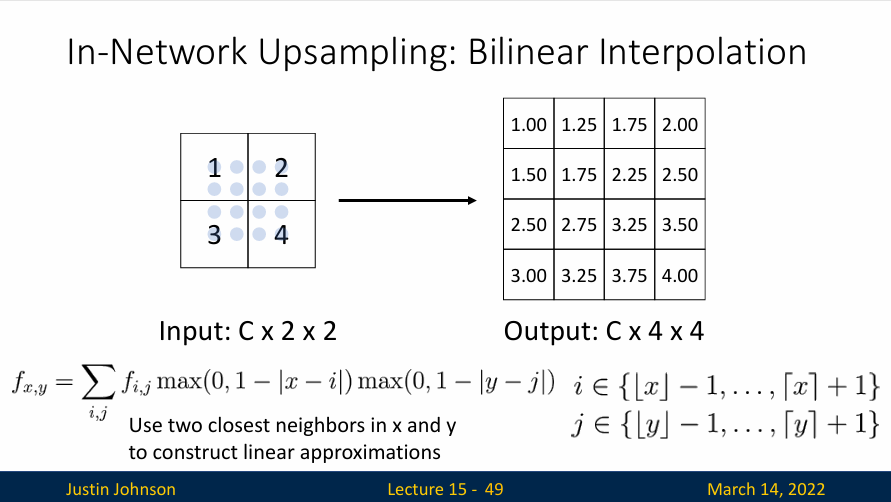
举个例子,如果我们想在一个2x2的像素格子中插入一个新的像素,我们可以先在水平方向上,对左侧像素和右侧像素进行线性插值,然后在垂直方向上,对上侧像素和下侧像素进行线性插值,最后,我们就得到了新的像素的值。
相比于最近邻插值,双线性插值能够得到更加平滑的图像,因为它在插值过程中,考虑了像素之间的关系,能够更好地保留图像的细节信息。但同时,双线性插值的计算量也比最近邻插值要大一些。
双三次插值:它是一种更高级的插值方式,相比于最近邻插值和双线性插值,可以得到更加平滑、更少锯齿状的图像。
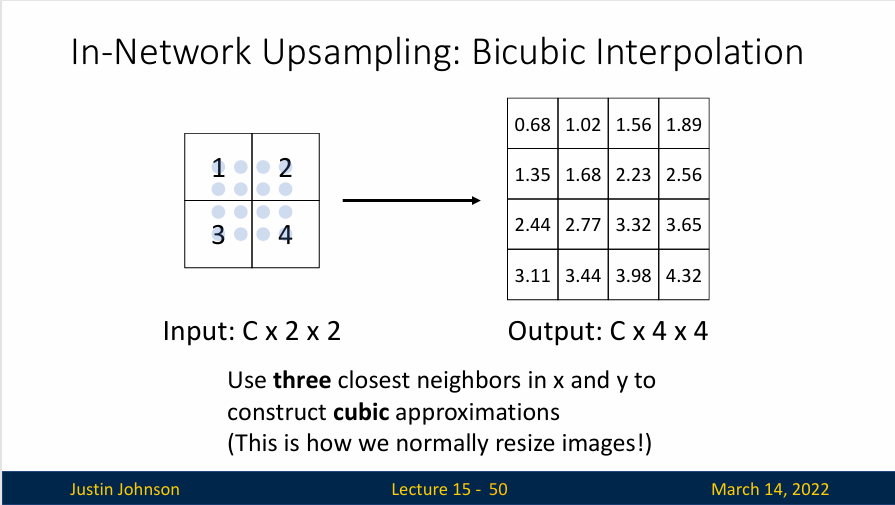
在双三次插值中,新的像素值是通过考察附近16个像素(在一个4x4的区域内)并使用这些像素的值进行加权计算得到的。具体的加权系数由三次插值函数决定,这个插值函数考虑到了像素之间的距离关系。
由于双三次插值考虑了更多的邻近像素,并且使用了更为复杂的插值函数,所以它能够得到更加精细、更为平滑的图像。但是,双三次插值的计算复杂度也较高,需要更多的计算资源。
最大反池化(Max Unpooling):这种方法的主要目的是恢复被池化(pooling)操作降低的图像分辨率。
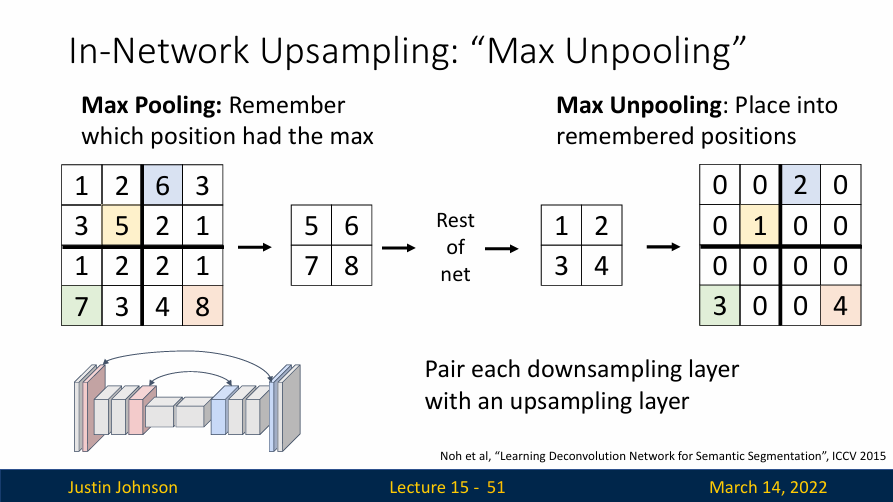
在最大池化(Max Pooling)操作中,输入的特征图被分成若干个非重叠的区域,每个区域内取最大值作为该区域的代表,这样能够大大减小特征图的尺寸。但在这个过程中,我们会丢失很多细节信息,这对于语义分割任务来说是不可接受的。
为了解决这个问题,我们可以使用最大反池化操作来恢复原来的图像尺寸。具体来说,最大反池化是这样进行的:首先,创建一个和原图像尺寸相同的空矩阵,然后,将池化操作中得到的最大值填充到对应的位置上,其他位置用零填充。这样,就能够得到一个和原图像尺寸相同的特征图。
值得注意的是,最大反池化操作需要记录最大池化操作中的最大值位置,这是因为我们需要在反池化过程中将最大值放回原来的位置。因此,最大反池化操作通常与最大池化操作配合使用。
在语义分割任务中,下采样和上采样操作通常会配合使用,以形成一个编码-解码(Encoder-Decoder)的结构。这种结构也被称为 U-Net 结构,因为它的形状类似于字母"U"。
在编码阶段(即下采样阶段),网络通过连续的卷积层和池化层来提取输入图像的语义特征。这些操作可以将图像的空间维度(即高度和宽度)降低,同时提升图像的深度(即通道数),使得网络能够捕捉到更抽象的特征。然而,这个过程会导致图像的空间信息丢失,这对于语义分割任务来说是不可接受的。
为了恢复图像的空间信息,网络在解码阶段(即上采样阶段)使用一系列的反卷积操作或上采样操作,以将特征图的空间维度恢复到与原始输入图像相同的尺寸。在这个过程中,网络通常会将上采样后的特征图与对应的下采样阶段的特征图进行拼接或相加,这被称为跳跃连接(skip connection)。这种方法可以帮助网络更好地保留低级别的空间信息,从而提高分割的精度。
经验法则是,如果你如果在下采样部分使用平均池化这种,那么上采样就可以考虑最近邻或者双线性或者双三次插值,如果下采样是最大池化,那么应该考虑使用最大反池化作为上采样方式
Learnable Upsampling
上面这些上采样运算,并没有任何可学习的参数,都是固定的运算,但是这里有一种转置卷积的上采样方法,可以通过某种方法进行学习
什么是可学习的卷积呢?
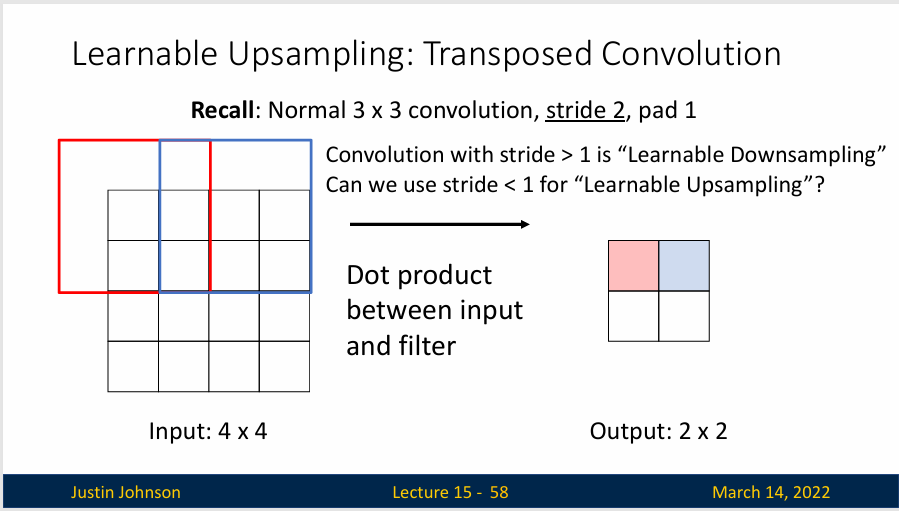
步长大于等于1的卷积,实际上就是一个可学习的下采样操作,提取特征,而可学习的这个属性意味着网络可以学习如何最好地进行下采样,以便最大化某些任务的性能。卷积核的参数(权重)在训练过程中通过学习数据自动更新,以提取特征。这些参数通过学习数据子哦对那个更新以提取特征。
但是,如果我们的步长小于1呢?这样,卷积可以通过某种方式,为输入中的每个点跨越输出中的多个点,如果我们能想出一种方法来做到这一点,那么是不是就可以实现一种可学习的上采样操作?
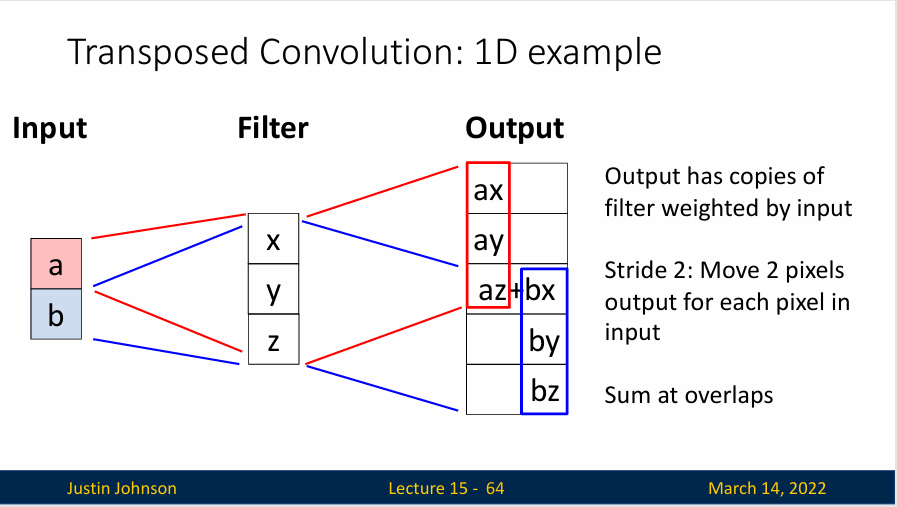
转置卷积(Transposed Convolution) 就是一种可学习卷积。转置卷积的基本原理是在输入特征图上进行“错位扫描”,通过这种方式,转置卷积的输出结果在形状上会比输入大,从而实现上采样。它的工作方式是这样的,首先输入一个低分辨率的数据,想输出一个高分辨率的数据,不过与常规卷积不同,我们这里是使用输入张量中的元素乘以转置卷积核(标量乘以张量),然后得到输出,并且将数值复制到输出张量的相应位置上,然后我们在输入中移动一个位置,在输出中移动两个位置,再次执行反卷积操作,如果有重合的地方,则进行求和。
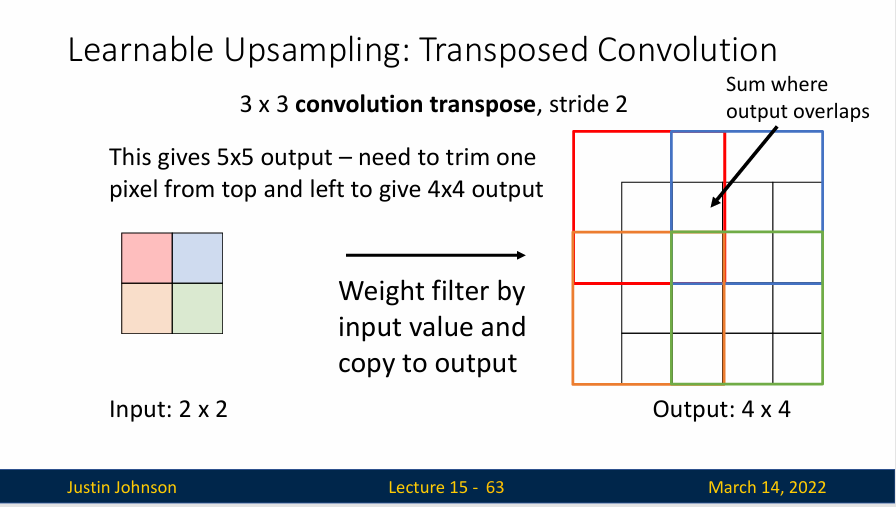
还有另一个视角:
我们可以将卷积操作表示成一类矩阵乘法,而转置卷积则可以表示成如下形式:
当步长为1时,转置卷积就是正常的卷积操作
Instance Segmentation
在计算机视觉和语义分割中,"stuff"和"thing"是两种不同类型的语义类别

"Thing"通常指的是可数的、有独立存在的物体,如人、汽车、自行车等。这些对象通常有明确的形状和大小,而且在图像中可以被清晰地辨识出来,可以区分为不同的实例(Instance)。
相反,"Stuff"指的是不可数的、通常作为背景存在的物体,如草地、天空、路面等。这些对象通常没有明确的形状和大小,而且在图像中可能会覆盖较大的区域,这些对象讨论数量或者个体是没有意义的。
在进行语义分割时,我们需要区分这两种类型的语义类别。对于"Thing",我们的目标通常是找出图像中的每个独立对象并给它们分配相应的类别。对于"Stuff",我们的目标通常是识别出图像中的每个区域并给它们分配相应的类别。
在某些情况下,"Stuff"和"Thing"的区分可能会变得模糊。例如,当我们看到一群密集的鸟时,我们可能会把它们视为一整块"Stuff",而不是单独的"Thing"。在这种情况下,如何进行语义分割就需要根据具体的任务和数据集来确定了。
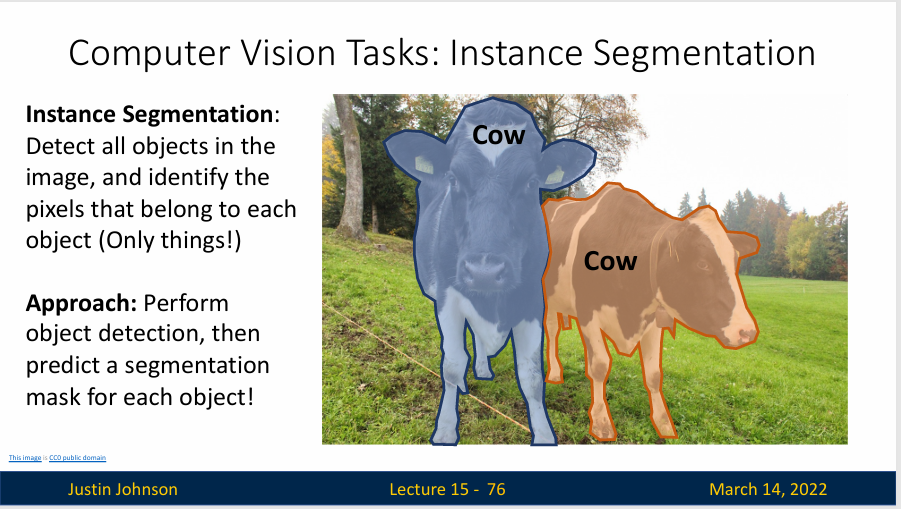
我们已经了解了目标检测和语义分割,前者可以区分不同对象实例,后者分割不同类别,但是抛弃了实例的概念,所以需要一种更高级的算法来实现目标检测+语义分割,也就是既要区分不同对象,也要完成像素级分割,也就是实例分割(Instance Segmentation)
实例分割的目标是对图像中的每个独立对象实例进行识别和分割,即使这些对象属于同一类别,实例分割也能够区分它们。与语义分割不同,语义分割只关注于类别级别的像素分类,而实例分割则进一步区分同一类别中的不同实例
实例分割算法主要分为两大类:
- 自上而下的方法(Top-Down Approach):首先通过目标检测定位出每个实例的大致位置(bounding box),然后在这些区域内进行语义分割以获得每个实例的精确掩码(mask)。
- 自下而上的方法(Bottom-Up Approach):首先进行逐像素的分类(类似于语义分割),然后通过聚类或其他度量学习手段区分同类中的不同实例
我们想实现实例分割,就需要基于目标检测算法,对于每一个检测出的对象,输出一个分割掩码(segmentation mask)
Mask R-CNN
Mask R-CNN 就是一个很经典的实例分割算法,他是一个两阶段的框架,扩展自 Faster R-CNN。在第一阶段,它扫描图像并生成提议(proposals),即有可能包含目标的区域。在第二阶段,它对这些提议进行分类,并生成边界框和掩码,与 Faster R-CNN 相比,Mask R-CNN 增加了一个分支网络,用于预测每个区域提议的像素级掩码,从而实现实例分割。
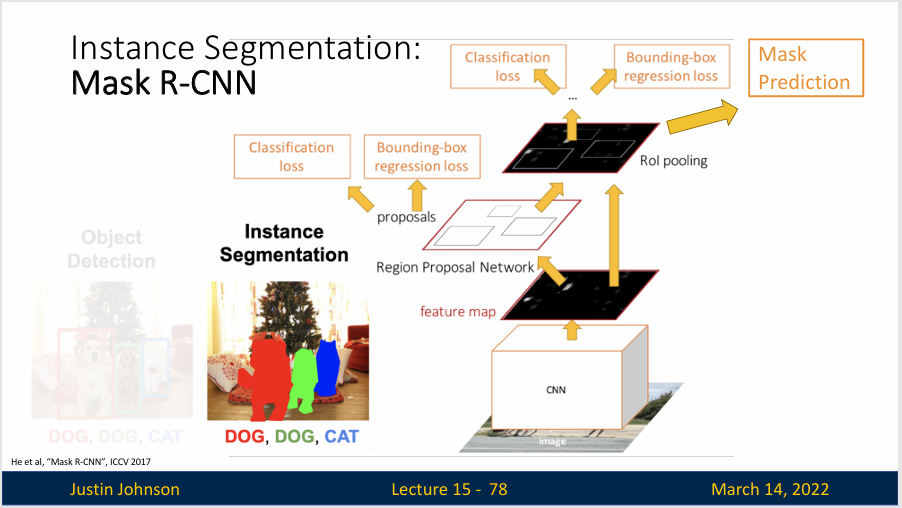
具体工作方式是这样的,我们仍然通过骨干网络提取网络特征,然后使用RPN预测候选区域,然后通过RoI对齐来获得特征图,然后在每个候选区域上运行一个小的语义分割网络,这个网络会为检测到的对象来预测一个分割掩码
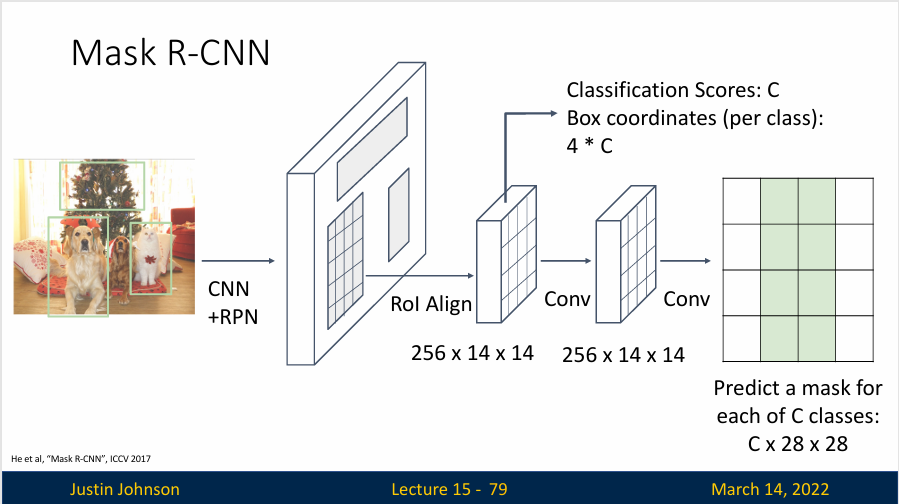
看起来,Mask R-CNN有点像目标检测和语义分割联合起来了,我们只是对检测到的对象进行语义分割,这意味着训练这些分割掩码的目标就是与候选区域的边界框对齐
如下图所示,红色边界框中是我们想检测的对象,我们的目标就是让分割掩码与检测到的对象的边界对齐

这是一个非常好的算法,他不但会使用目标检测方法完成边界框的输出,对于每个边界框,实际上也会输出分割掩码来告诉我们,边界框中的哪些像素实际上对应检测到的对象
尽管Mask R-CNN在精度上具有优势,但也存在一些局限性,如计算资源消耗相对较大,尤其是对于高分辨率图像,实时性相对较差。此外,对小目标检测的敏感度不如一些针对性设计的小目标检测算法。
总结来说,Mask R-CNN作为一个灵活的框架,它不仅可以完成实例分割任务,还可以扩展到目标分类、目标检测、语义分割等多种任务,是深度学习在目标检测和实例分割领域的杰出代表。随着硬件性能的提升和算法优化的深入,Mask R-CNN有望在更多实际应用场景中发挥关键作用。
Panoptic Segmentation
全景分割(Panoptic Segmentation) 是一项结合了语义分割和实例分割的计算机视觉任务,旨在为图像中的每个像素分配一个语义标签和一个唯一的实例标识符,他要求图像中的每个像素点都必须被分配给一个语义标签和一个实例id。其中,语义标签指的是物体的类别,而实例id则对应同类物体的不同编号。这种分割方式不仅区分了背景(stuff类别)和前景(things类别),而且还为每个可数的目标(如车辆、行人)分配了唯一的标识符

实例分割和全景分割的主要区别在于全景分割更加全面,它同时处理了语义分割和实例分割两种任务。实例分割主要关注"thing"类别的识别和分割,而全景分割则旨在对所有的像素点进行准确的分类和分割。
Applications
Keypint Estimation
有时候,大家对于确定图像中人体的确切姿态更感兴趣,这个可以使用关键点检测的方式来完成
我们首先分割出不同的人体实例,然后使用某种方法去估计其姿势,常用的一种方法就是定义一组关键点,比如说眼睛、鼻子和各种关节

想完成这一步的一种方法,就是使用Mask R-CNN实现关键点检测,我们可以在Mask R-CNN上再加一个关键点预测网络来预测关键点
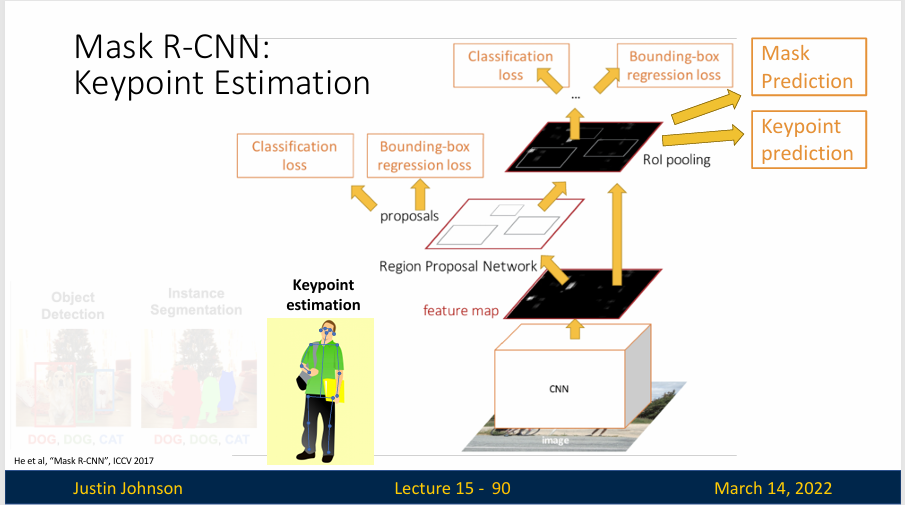
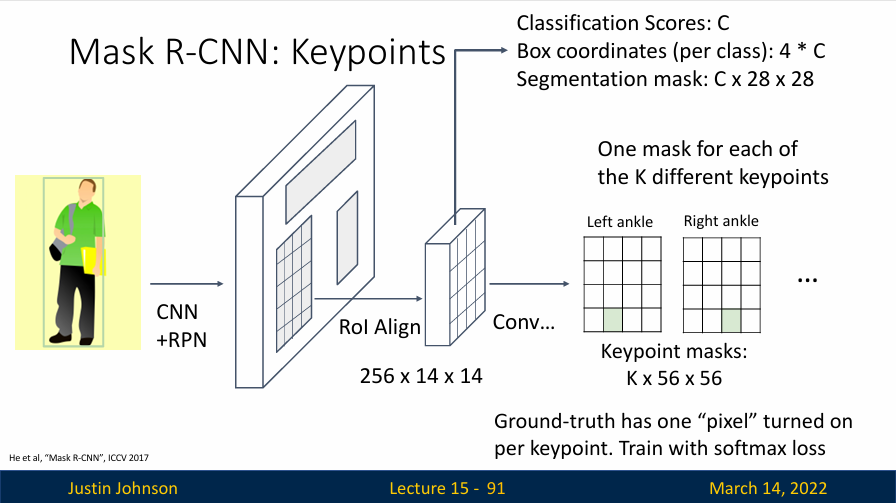
这个新加入的网络,只是预测十七个关键点,因为我们认为想确定人体姿态,十七个关键点就足够了,然后使用交叉熵损失训练
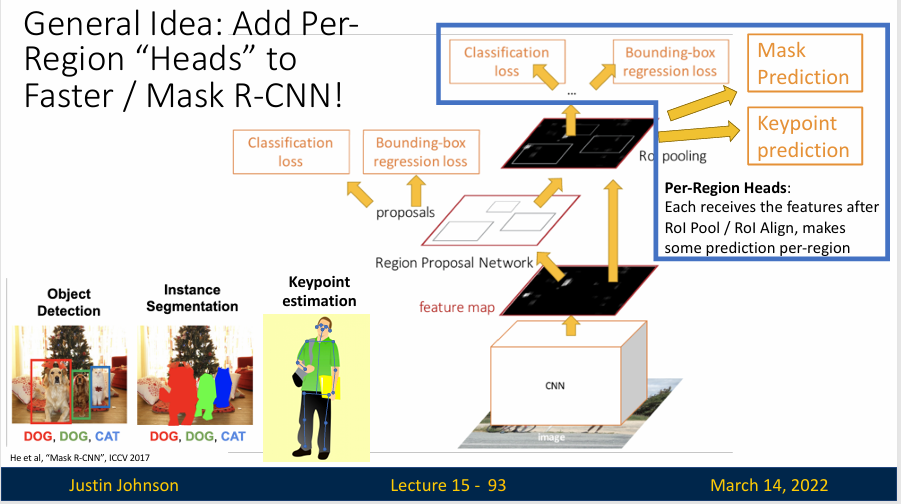
General Idea
我们现在有了一种很通用的想法,就是如果我们想在输入图像的不同区域做某些新颖类型的预测,那么就可以将其框定为一个目标检测任务,然后在目标检测器上加一个“Heads”,这个“Heads”就可以在输入图像的每个区域产生额外的新型输出
Dense Captioning
有一个很好玩的想法,就是合并目标检测和图像字幕,输入一个图像,然后输出一种自然语言来描述输入图像中的不同区域
你可以通过将LSTM这种模型添加到特征区域顶部来实现

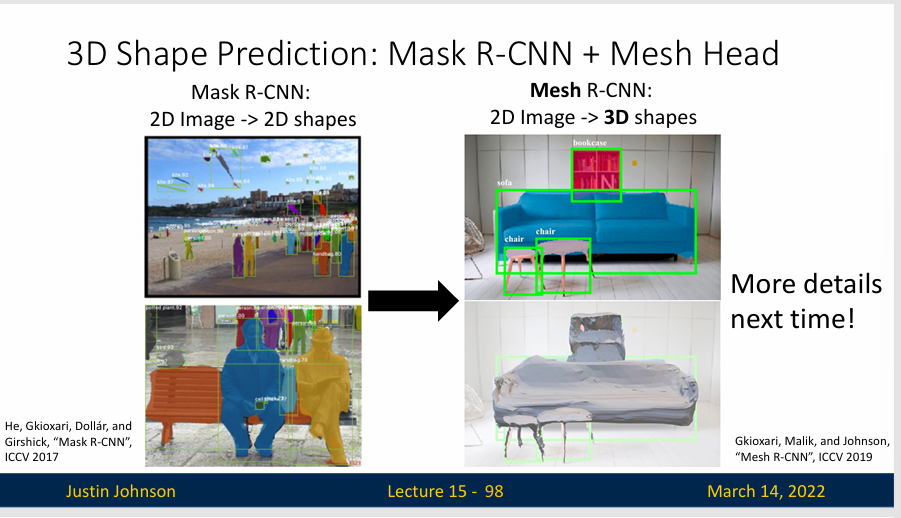
3D Shape Prediction
Mesh R-CNN是基于Mask R-CNN改进而来,增加了网格预测分支,够从单一的2D图像中检测出目标并输出每个目标的3D三角形网格。这种方法可以在仅有RGB图像输入的情况下,同时实现目标检测、实例分割和物体3D三角网格预测的功能
esh R-CNN的核心是网格预测器,它利用输入的对齐的图像特征,输出物体的三维网格。同时保证了特征在不同阶段的对齐,包括区域(RoIAlign)和体素(VertAlign)的对齐操作。每个预测出的网格都有自己的拓扑结构(种类、顶点、边和面)和几何形状。
Mesh R-CNN摒弃了使用固定网格模板预测形态的方法,而是利用多种三维表达方法完成预测。首先模型预测出粗糙的目标体素,然后转换成网格并对其进行细化