马尔可夫链蒙特卡罗法
约 5886 个字 2 张图片 预计阅读时间 39 分钟
蒙特卡罗法
蒙特卡罗法要解决的问题是,假设概率分布的定义己知,通过抽样获得概率分布的随机样本,并通过得到的随机样本对概率分布的特征进行分析。其核心是随机抽样(random sampling)
接受-拒绝抽样法
假设有随机变量 \(x\) ,取值 \(x∈\mathcal{X}\),其概率密度函数为 \(p(x)\) ,目标是得到该概率分布的随机样本,以对这个概率分布进行分析。
接受-拒绝法的基本想法是:假设 \(p(x)\) 不可以直接抽样,找一个可以直接抽样的分布,称为建议分布,记其对应概率密度函数 \(q(x)\) ,\(q(x)\) 的 \(c\) 倍一定大于等于 \(p(x)\) ,其中 \(c>0\) 按照建议分布 \(q(x)\) 进行抽样,假设得到结果是 \(x^∗\),再按 \(\frac{{p(x^∗ )}}{cq(x^∗ )}\) 的比例随机决定是否接受 \(x^∗\)(一般是选取一个分布进行比较) ;接受-拒绝法实际是按照 \(p(x)\) 的涵盖面积(或涵盖体积)占 \(cq(x)\) 的涵盖面积(或涵盖体积)的比例进行抽样。
接受-拒绝抽样法
输入:抽样的目标概率分布的概率密度函数 \(p(x)\);
输出:概率分布的随机样本 \(x_1,x_2,⋯,x_n\)。
参数:样本数 \(n\)
- 选择概率密度函数为 \(q(x)\) 的概率分布,作为建议分布,使其对任一 \(x\) 满足\(cq(x)≥p(x)\),其中\(c>0\)。
- 按照建议分布 \(q(x)\) 随机抽样得到样本 \(x^∗\) ,再按照均匀分布在 \((0,1)\) 范围内抽样得到 \(u\)。
- 如果\(u≤\frac{{p(x^∗ )}}{cq(x^∗ )}\) ,则将 \(x^∗\) 作为抽样结果;否则,回到步骤(2)。
- 直至得到 \(n\) 个随机样本,结束。
接受-拒绝法的优点:容易实现,缺点:效率可能不高。如果 \(p(x)\) 的涵盖体积占 \(cq(x)\) 的涵盖体积的比例很低,就会导致拒绝的比例很高,抽样效率很低。
蒙特卡罗法
假设有随机变量 \(x\) ,取值 \(x \in \mathcal{X}\) ,其概率密度函数为 \(p(x)\) ,\(f(x)\) 为定义在 \(\mathcal{X}\) 上的函数,目标是求函数 \(f(x)\) 关于密度函数 \(p(x)\) 的数学期望 \(\mathbb{E}_{p(x)}[f(x)]\)
蒙特卡罗法按照概率分布 \(p(x)\) 独立地抽取 \(n\) 个样本,\(x_{1},x_{2},\dots x_{n}\) ,计算函数的样本均值:
根据大数定律可知,当样本容量增大时,样本均值以概率1收敛于数学期望,可得数学期望的近似计算方法:
一般的蒙特卡罗法也可以用于定积分的近似计算,称为蒙特卡罗积分(Monte Carlo integration)。假设计算函数 \(h(x)\) 的定积分 \(\int_{\mathcal{X}}h(x)\mathrm{d}x\) ,如果能将函数 \(h(x)\) 分解成一个函数 \(f(x)\) 和一个概率密度函数 \(p(x)\) 的乘积形式,有:
于是函数 \(h(x)\) 的积分就可以表示为函数 \(f(x)\) 关于概率密度函数 \(p(x)\) 的数学期望。而函数的数学期望又可以通过函数的样本均值估计,于是就可以利用样本均值来近似计算积分,这就是蒙特卡罗积分的基本思想:
马尔可夫链
Markov 链
假设在时刻 \(0\) 的随机变量 \(X_0\) 遵循概率分布 \(P(X_0 )=π_0\),称为初始状态分布。在某个时刻 \(t≥1\) 的随机变量 \(X_t\) 与前一个时刻的随机变量 \(X_{t-1}\) 之间有条件分布 \(P(X_t |X_{t-1} )\), 如果 \(X_t\) 只依赖于 \(X_{t-1}\),而不依赖于过去的随机变量 \(\{X_0,X_1,⋯,X_{t-2} \}\) ,这一性质称为马尔可夫性,即
具有马尔可夫性的随机序列 \(\{X_0,X_1,⋯,X_{t-2} \}\) 称为马尔可夫链(Markov chain),或马尔可夫过程(Markov process)。条件概率分布 \(P(X_{t}|X_{t-1})\) 称为马尔可夫链的转移概率分布。转移概率分布决定了马尔可夫链的特性。
马尔可夫性的直观解释是“未来只依赖于现在,而与过去无关”。
当马氏链的一步转移概率\(P\{X_{t+1}=i|X_t = j\}\)只与状态 \(i,j\) 有关, 而与 \(t\) 无关时, 称此马氏链为时齐马氏链,记 \(P\{X_{t+1}=i|X_t = j\} = p_{ij}\),代表处于状态 \(j\) 的过程下一步转移到状态 \(i\) 的概率. 若 \(P\{X_{t+1}=i|X_t = j\}\) 与 \(n\) 有关, 就称该马氏链为非时齐的.
马尔可夫链的转移概率 \(p_{ij}\) 可以由矩阵表示:
称为马尔可夫链的转移概率矩阵,满足 \(p_{ij}>0,\sum_{i}^{}p_{ij}=1\) (矩阵列元素之和为 \(1\) )
记时刻 \(t\) 的状态分布:
其中 \(\pi_{i}(t)\) 表示时刻 \(t\) 状态为 \(i\) 的概率 \(P(X_{t}=i)\) ,即
有限离散状态的马尔可夫链可以由有向图表示
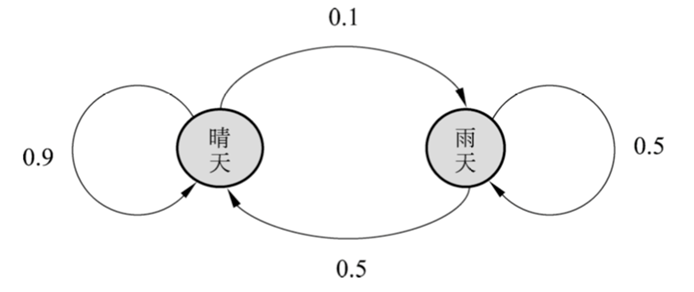
马尔可夫链实际上是刻画随时间在状态之间转移的模型,假设未来的转移状态只依赖于现在的状态,而与过去的状态无关。马尔可夫链 \(X\) 在时刻 \(t\) 的状态分布,可以由在时刻 \((t-1)\) 的状态分布以及转移概率分布决定:
平稳分布
设有马尔可夫链 \(X = \left\{ X_{0},X_{1},\dots,X_{t},\dots \right\}\) ,其状态空间为 \(\mathcal{S}\) ,转移概率矩阵为 \(P=(p_{ij})\) ,如果存在状态空间 \(\mathcal{S}\) 上的一个分布:
使得:
则称 \(\pi\) 为马尔科夫链 \(X=\left\{X_{0},X_{1},\dots,X_{t},\dots\right\}\) 的平稳分布。
直观上,如果马尔可夫链的平稳分布存在,那么以该平稳分布作为初始分布,面向未来进行随机状态转移,之后任何一个时刻的状态分布都是该平稳分布。
Corollary
给定一个马尔可夫链 \(X = \left\{ X_{0},X_{1},\dots,X_{t},\dots \right\}\) ,其状态空间为 \(\mathcal{S}\) ,转移概率矩阵为 \(P=(p_{ij})\) ,则分布 \(\pi = (\pi_{1},\pi_{2},\dots)^{T}\) 是 \(X\) 的平稳分布的充分必要条件是 \(\pi = (\pi_{1},\pi_{2},\dots,)^{T}\) 是下列方程组的解:
引理给出了一个求马尔可夫链平稳分布的方法。马尔可夫链可能存在唯一平稳分布、无穷多个平稳分布,或不存在平稳分布。(当离散状态马尔可夫链有无穷多个状态,有可能没有平稳分布。)
连续状态马尔可夫链 \(X=\left\{ X_{0},X_{1},\dots,X_{t},\dots \right\}\) 定义在连续状态空间 \(\mathcal{S}\) ,转移概率分布由转移概率核或转移核表示。
转移核定义为:
其中 \(p(x,\cdot)\) 表示概率密度函数,满足 \(p(x,\cdot)\geq {0},P(x,\mathcal{S} )= \int_{\mathcal{S}}=p(x,y)\mathrm{d}y =1\) 。转移核表示从 \(x\sim A\) 的转移概率
同样可以定义马尔可夫链上的平稳分布:
性质
不可约
设由马尔可夫链 \(X=\left\{ X_{0},X_{1},\dots,X_{t},\dots \right\}\),状态空间为 \(\mathcal{S}\) ,对于任意状态 \(i,j\in \mathcal{S}\) ,如果存在一个时刻满足
也就是说,时刻 \(0\) 从状态 \(j\) 出发,时刻 \(t\) 到状态 \(i\) 的概率大于 \(0\) ,则称此马尔可夫链 \(X\) 是不可约的,否则称马尔可夫链可约。
直观上,一个不可约的马尔可夫链,从任意状态出发,当经过充分长时间后,可以到达任意状态。
周期性
设由马尔可夫链 \(X=\left\{ X_{0},X_{1},\dots,X_{t},\dots \right\}\),状态空间为 \(\mathcal{S}\) ,对于任意状态 \(i\in \mathcal{S}\) ,如果时刻 \(0\) 从状态 \(i\) 出发,\(t\) 时刻返回状态的所有时间长 \(\left\{ t:P(X_{t}=i|X_{0}=i)>0 \right\}\) 的最大公约数是 \(1\) ,则称此马尔可夫链 \(X\) 是非周期的,否则称马尔可夫链是周期的。
直观上,一个非周期性的马尔可夫链,不存在一个状态,从这一个状态出发,再返回到这个状态时所经历的时间长呈一定的周期性.
Example
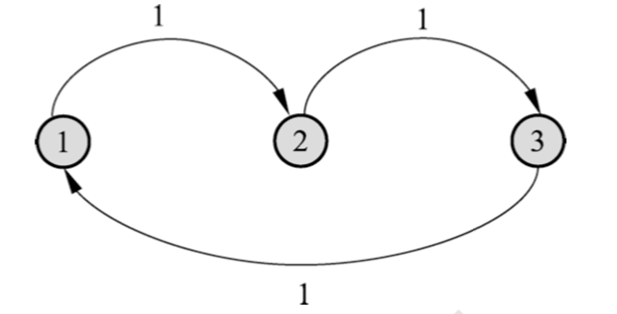
上述马尔可夫链的转移概率矩阵为
其平稳分布:\(\pi=\left( \frac{1}{3} \quad \frac{1}{3} \quad \frac{1}{3} \right)\) 此马尔可夫链从每个状态出发返回该状态的时刻是 3 的倍数,具有周期性。
利用这两个性质可以推出如下定理:
Theorem
不可约且非周期的有限状态马尔可夫链,有唯一平稳分布存在。
正常返
设有马尔可夫链 \(X=\{X_0,X_1,⋯,X_t,⋯\}\),状态空间为 \(\mathcal{S}\) ,对于任意状态 \(i,j∈\mathcal{S}\),定义概率 \(p_{ij}^t\) 为时刻 \(0\) 从状态 \(j\) 出发,时刻 \(t\) 首次转移到状态 \(i\) 的概率,即 \(p_{ij}^{t}= P(X_{t }=i,X_{s}\neq i ,s=1,2,\dots,t-1|X_{0}=j)\) 。若对所有状态 \(i,j\) 都满足 \(\lim_{ t \to \infty } p_{ij}^{t}>0\) ,则称马尔可夫链 \(X\) 是正常返的(positive recurrent)。
一个正常返的马尔可夫链,其中任意一个状态,从其他任意一个状态出发,当时间趋于无穷时,首次转移到这个状态的概率不为 \(0\)
根据这个性质可以得出无限状态下马尔可夫链存在唯一平稳分布的条件:
theorem
不可约、非周期且正常返的马尔可夫链,有唯一平稳分布存在。
遍历定理
设有马尔可夫链 \(X=\{X_0,X_1,⋯,X_t,⋯\}\),状态空间为 \(\mathcal{S}\) ,若马尔可夫链 \(X\) 是不可约、非周期且正常返的,则该马尔可夫链有唯一平稳分布 \(\pi=(\pi_{1},\pi_{2},\dots)^{T}\),并且转移概率的极限分布是马尔可夫链的平稳分布。
若 \(f(X)\) 是定义在状态空间上的函数,\(\mathbb{E}_{\pi}[\lvert f(X) \rvert]< \infty\) ,则
这里
\(\mathbb{E}_{\pi}[f(X)]=\sum_{i}^{}f(i)\pi_{i}\) 是 \(f(X)\) 关于平稳分布 \(\pi = (\pi_{1},\pi_{2},\dots)^{T}\) 的数学期望。
遍历定理的直观解释:满足相应条件的马尔可夫链,当时间趋于无穷时,马尔可夫链的状态分布趋近于平稳分布,随机变量的函数的样本均值以概率 \(1\) 收敛于该函数的数学期望。样本均值可以认为是时间均值,而数学期望是空间均值。
遍历定理实际表述了遍历性的含义:当时间趋于无穷时,时间均值等于空间均值。遍历定理的三个条件:不可约、非周期、正常返,保证了当时间趋于无穷时达到任意一个状态的概率不为 \(0\) 。
但实际上,并不知道经过多少次迭代后,马尔可夫链的状态分布才能接近于平稳分布,在实际应用遍历定理时,取一个足够大的整数 \(m\) ,经过 \(m\) 次迭代后认为状态分布就是平稳分布。
可逆马尔可夫链
设有马尔可夫链 \(X = \left\{ X_{0},X_{1},\dots,X_{t},\dots \right\}\) ,其状态空间为 \(\mathcal{S}\) ,转移概率矩阵为 \(P\) ,如果有状态分布 \(\pi = (\pi_{1},\pi_{2},\dots)^{T}\) ,对于任意状态 \(i,j\in \mathcal{S}\) ,对任意一个时刻 \(t\) 满足:
或者:
则称则称此马尔可夫链 \(X\) 为可逆马尔可夫链(reversible Markov chain),上式也称细致平衡方程。
直观上,如果有可逆的马尔可夫链,那么以该马尔可夫链的平稳分布作为初始分布,进行随机状态转移,无论是面向未来还是面向过去,任何一个时刻的状态分布都是该平稳分布
下面定理给出了细致平衡方程求法:
Theorem
满足细致平衡方程的状态分布 \(π\) 就是该马尔可夫链的平稳分布。即
可逆马尔可夫链一定有唯一平稳分布,给出了一个马尔可夫链有平稳分布的充分条件(不是必要条件)
马尔可夫链蒙特卡罗法
马尔可夫链蒙特卡罗法更适合于随机变量是多元的、密度函数是非标准形式的、随机变量各分量不独立等情况。假设多元随机变量 \(x\) ,\(x \in \mathcal{X}\) ,其概率密度函数为 \(p(x),f(x)\) 为定义在 \(x\in \mathcal{X}\) 上的函数,目标是获取概率分布 \(p(x)\) 的样本集合,以及求函数 \(f(x)\) 的数学期望 \(\mathbb{E}_{p(x)}[f(x)]\)
马尔可夫链蒙特卡罗法的基本想法:在随机变量 \(x\) 的状态空间上 \(\mathcal{S}\) 上定义一个满足遍历定理的马尔可夫链 \(X =\left\{ X_{0},X_{1},\dots,X_{t},\dots \right\}\),使其平稳分布就是抽样的目标分布 \(p(x)\) 。然后在这个马尔可夫链上进行随机游走,每个时刻得到一个样本。根据遍历定理,当时间趋于无穷时,样本的分布趋近平稳分布,样本的函数均值趋近函数的数学期望。
所以,当时间足够长时(时刻大于某个正整数 \(m\) ),在之后的时间(时刻小于等于某个正整数 \(n\),\(n>m\))里随机游走得到的样本集合 \(\{x_{m+1},x_{m+2},⋯,x_n \}\) 就是目标概率分布的抽样结果。得到的函数均值就是要计算的数学期望:
到时刻 \(m\) 为止的时间段称为燃烧期。
构建马尔可夫链的一个方法是定义特殊的转移核函数或者转移矩阵,构建可逆马尔可夫链,这样可以保证遍历定理成立。
马尔可夫链蒙特卡罗法的收敛性的判断通常是经验性的
马尔可夫链蒙特卡罗法中得到的样本序列,相邻的样本点是相关的,而不是独立的。马尔可夫链蒙特卡罗法比接受-拒绝法更容易实现,因为只需要定义马尔可夫链, 而不需要定义建议分布。一般来说马尔可夫链蒙特卡罗法比接受-拒绝法效率更高,没有大量被拒绝的样本,尽管要抛弃燃烧期的样本。
马尔可夫链蒙特卡罗法的基本步骤
- 首先,在随机变量 \(x\) 的状态空间 \(\mathcal{S}\) 上构造一个满足遍历定理的马尔可夫链, 使其平稳分布为目标分布 \(p(x)\) 。
- 从状态空间的某一点 \(x_0\) 出发,用构造的马尔可夫链进行随机游走,产生样本序列\(x_0,x_1,⋯,x_t,⋯\)。
- 应用马尔可夫链的遍历定理,确定正整数 \(m\) 和 \(n\) ,\((m<n)\),得到样本集合 \({x_{m+1},x_{m+2},⋯,x_n }\) ,求得函数 \(f(x)\) 的均值(遍历均值)
一般地, 对高维或取值空间 \(\mathcal{X}\) 结构复杂的随机向量 \(\mathcal{X}\) , MCMC方法构造取值于的马氏链, 使其平稳分布为 \(\mathcal{X}\) 的目标分布。 模拟此马氏链, 抛弃开始的部分抽样值, 把剩余部分 \(X\) 作为的非独立抽样。 非独立抽样的估计效率比独立抽样低。
MCMC方法的关键在于如何从第 \(t\) 时刻转移到第 \(t+1\) 时刻。 好的转移算法应该使得马氏链比较快地收敛到平稳分布, 并且不会长时间地停留在取值空间 \(\mathcal{X}\) 的局部区域内 (在目标分布是多峰分布且峰高度差异较大时容易出现这种问题)。
Metropolis-Hasting方法(MH方法)是一个基本的MCMC算法, 此算法在每一步试探地进行转移(如随机游动), 如果转移后能提高状态 \(x_{t}\) 在目标分布 \(\pi\) 中的密度值则接受转移结果, 否则以一定的概率决定是转移还是停留不动。
Gibbs抽样是另外一种常用的MCMC方法,此方法轮流沿各个坐标轴方向转移, 且转移概率由当前状态下用其它坐标预测转移方向坐标的条件分布给出。 因为利用了目标分布的条件分布, 所以Gibbs抽样方法的效率比MH方法效率更高。
摘自参考资料
Metropolis-Hastings算法
假设要抽样的概率分布为 \(p(x)\) ,Metropolis-Hastings 算法采用转移核为 \(p(x,x')\) 的马尔可夫链
其中 \(q\) 和 \(\alpha\) 分别称为建议分布(proposal distribution)和接受分布 (acceptance distribution)
接受分布:
这时候转移核写作:
转移核 \(p(x,x')\) 的马尔可夫链上的随机游走以以下方式进行:如果在时刻 \((t-1)\) 处于状态 \(x\) ,即 \(X_{t-1}=x\) ,则先按建议分布 \(q(x,x')\) 抽样产生一个候选状态 \(x'\) ,然后按照接受分布 \(\alpha(x,x')\) 抽样决定是否接受状态 \(x'\) :以概率 \(\alpha(x,x')\) 接受 \(x'\) ,决定时刻 \(t\) 转移到状态 \(x'\) ;以概率 \(\alpha(x,x')\) 拒绝 \(x'\) ,决定时刻 \(t\) 仍停留状态 \(x\) 。
具体地,从区间 \((0,1)\) 上的均匀分布中抽取一个随机数 \(u\) ,决定时刻 \(t\) 的状态:
可以证明,转移核 \(p(x,x')\) 的马尔可夫链是可逆马尔可夫链(满足遍历定理), 其平稳分布就是 \(p(x)\) ,即要抽样的目标分布。也就是说这是马尔可夫链蒙特卡罗法的一个具体实现。
现在考虑建议分布,建议分布 \(q\) 一般是另一个马尔可夫链的转移核,且是不可约、容易抽样的分布。一种假设是假设建议分布是对称的,即对任意的 \(x\) 和 \(x'\) ,有 \(q(x,x')=q(x',x)\) ,这种分布称为 Metropolis 选择,一个特例是选择:
比如高斯分布,这种算法称为随机游走 Metropolis 算法,Metropolis选择的特点是当 \(x'\) 与 \(x\) 接近时, \(q(x,x')\) 的概率值高,否则 \(q(x,x')\) 的概率值低。状态转移在附近点的可能性更大。
还有一种形式称为独立抽样,假设 \(q(x,x')\) 与当前状态 \(x\) 无关,即取 \(q(x,x')=q(x')\) ,独立抽样实现简单,但可能收敛速度慢,通常选择接近目标分布 \(p(x)\) 的分布作为建议分布\(q(x)\)。
满条件分布
马尔可夫链蒙特卡罗法的目标分布通常是多元联合概率分布 \(p(x)=p(x_{1},x_{2},\dots x_{k})\) ,其中 \(x=(x_{1},x_{2},\dots,x_{k})^{T}\) 为 \(k\) 维随机变量,如果条件概率分布 \(p(x_{I}|x_{-I})\) 中所有 \(k\) 个变量出现,其中 \(x_{I}=\left\{ x_{i},i\in I \right\},x_{-I}=\left( x_{i}\not\in I \right),I \subset K =\left\{ 1,2,\dots,k \right\}\) 那么称这种条件概率分布维满条件分布。
满条件分布有以下性质:对任意 \(x,x' \in \mathcal{X}\) 和任意 \(I \subset K\) ,有:
而且,对任意 \(x,x' \in \mathcal{X}\) 和任意的 \(I \subset K\) ,有:
Metropolis-Hastings算法
输入:抽样的目标分布的密度函数 \(p(x)\) ,函数 \(f(x)\)
输出:\(p(x)\) 的随机样本 \(x_{m+1},x_{m+2},\dots x_{n}\) ,函数样本均值 \(f_{mn}\)
参数:收敛步数 \(m\) ,迭代步数 \(n\)
- 选择一个初始值 \(x_{0}\)
- 循环执行
- 设状态 \(x_{i-1}=x\) ,按照建议分布随机抽取一个候选状态
- 计算接受概率\(\alpha(x,x') = \min \left\{ 1, \frac{p(x')q(x',x)}{p(x)q(x,x')} \right\}\)
- 从区间 \((0,1)\) 中按均匀分布随机抽取一个数 \(u\) ,如果 \(u\leq \alpha(x,x')\) 取 \(x_{i}=x'\) 否则 取 \(x_{i}= x\)
- 得到样本集合 \(\left\{ x_{m+1},x_{m+2},\dots x_{n} \right\}\) ,计算:
在Metropolis-Hastings算法中,通常需要对多元变量分布进行抽样,有时对多元变量分布的抽样是困难的。可以对多元变量的每一变量的条件分布依次分别进行抽样,从而实现对整个多元变量的一次抽样,这就是单分量Metropolis-Hastings (single-component Metropolis-Hastings)算法。
假设马尔可夫链的状态由 \(k\) 随机变量表示:
设在第 \((i-1)\) 次迭代结束时分量 \(x_{j}\) 的取值为 \(x_{j}^{(i-1)}\) ,在第 \(i\) 次迭代的第 \(j\) 步,对分量 \(x_{j}\) 根据 Metropolis-Hastings 算法更新,得到其新的取值 \(x^{(i)}_{j}\) :首先由建议分布抽样产生分量 \(x_{j}\) 的候选值 \(x'^{(i)}_{j}\) ,然后根据接受概率:
抽样决定是否接受候选值 \(x_{j}'^{(i)}\) ,如果接受,取 \(x_{j}^{(i)}=x_{j}'^{(i)}\) 否则,令 \(x_{j}^{(i)} = x_{j}^{(i-1)}\) 。马尔可夫链的转移概率为:
吉布斯抽样
吉布斯抽样用于多元变量联合分布的抽样和估计,可以认为是 MH 算法的特殊情况。
其基本做法是,从联合概率分布定义满条件概率分布,依次对满条件概率分布进行抽样,得到样本的序列。可以证明这样的抽样过程是在一个马尔可夫链上的随机游走,每一个样本对应着马尔可夫链的状态,平稳分布就是目标的联合分布。整体成为一个马尔可夫链蒙特卡罗法,燃烧期之后的样本就是联合分布的随机样本。
假设多元变量的联合概率分布为:
吉布斯抽样从一个初始样本出发,不断迭代,每次得到联合分布的一个样本
最终得到样本序列:\(\left\{ x^{(0)},x^{(1)},\cdots ,x^{(n)}\right\}\)。
在每次迭代中,依次对 \(k\) 个随机变量中的一个变量进行随机抽样。如果在第 \(i\) 次迭代中,对第 \(j\) 个变量进行随机抽样,那么抽样的分布是满条件概率分布 \(p(x_j |x_{-j}^{(i) } )\),这里 \(x_{-j}^{(i) }\) 表示第 \(i\) 次迭代中,变量 \(j\) 以外的其他变量。
设在第 \((i-1)\) 步得到样本 \(\left( x_{1}^{(i-1)},x_{2}^{(i-1)},\cdots,x_{k}^{(i-1)} \right)^{T}\),在 \(i\) 步,首先对第一个变量按照以下满条件概率分布随机抽样
得到 \(x_{1}^{(i)}\) ,之后依次对第 \(j\) 变量按照以下满条件概率分布随机抽样
得到 \(x_{j}^{(i)}\) ,最后对第 \(k\) 个变量按照以下满条件概率分布随机抽样
得到 \(x_{k}^{(i)}\) ,于是得到整体样本 \(x^{(i)}=\left( x_{1}^{(i)},x_{2}^{(i)},\cdots,x_{k}^{(i)} \right)^{T}\)
定义建议分布式当前变量 \(x_{j}\) 的满条件概率分布
此时接受概率 \(\alpha=1\) ,转移核实满条件概率分布 \(p(x,x')=p(x_{j}|x_{-j})\) 。
也就是说依次按照单变量的满条件概率分布 \(p(x_{j}'|x_{-j})\) 进行随机抽样,就实现单分量 MH 算法,吉布斯抽样对每次抽样的结果都接受,没有拒绝。
这里,假设满条件概率分布 \(p(x_{j}'|x_{-j})\) 不为零,即马尔可夫链是不可约的。
抽样计算
利用概率分布提高抽样的效率。
用 \(y\) 表示观测数据,\(\alpha,\theta,z\) 表示超参数、模型参数和未观测数据,贝叶斯学习的目的是求取后验概率最大的模型:
其中,\(p(\alpha)\) 是超参数分布,\(p(\theta|\alpha)\) 是先验分布,\(p(z,y|\theta)\) 是完全数据的分布。
如果用吉布斯抽样估计 \(p(x|y),x=(\alpha,\theta,z)\) 吉布斯抽样中各个变量 \(\alpha,\theta,z\) 的满条件分布满足:
依满条件概率分布的抽样可以通过依这些条件概率分布的乘积的抽样进行。这样可以大幅减少抽样的计算复杂度,因为计算只涉及部分变量.