Object Detection
约 4973 个字 14 张图片 预计阅读时间 33 分钟
目标检测 (Object Detection) 的任务时找出图像中所有感兴趣的目标(物体),确定它们的类别位置,这是计算机视觉领域的核心问题之一。由于各类物体有不同的外观、形状和姿态,加上成像时光照、遮挡等因素干扰,目标检测一直是计算机视觉领域最具有挑战性问题。
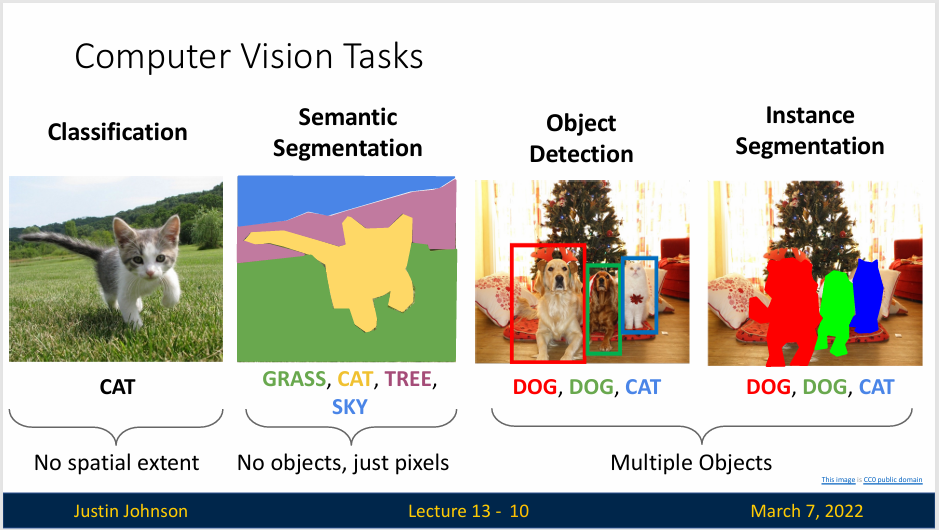
计算机视觉中关于图像识别有四大类问题:
- 分类(Classification):解决“是什么”的问题,即给定一张图片或一段视频,判断里面目标
- 语义分割(Semantic Segmentation):将图像中的每个像素分配给特定的语义类别,例如人、车、树等。
- 目标检测(Object Detection):在图像或视频中自动检测和识别物体的位置和类型。
- 实例分割(Instance Segmentation):在图像或视频分割出不同物体
Object Detection
我们输入一个彩色图像,输出是一组检测到的对象,我们希望所有的对象都可以识别到,比如说下图中,我们希望识别出图像所有的猫和狗,那么模型就应检测出来:

在目标检测中,我们希望能够输出两个内容:
- 类别标签(Category label):表示检测到的对象的类别,这是分类任务
- 边界框(Bounding box):给出图像中该对象的空间范围(或者说具体位置),这是定位任务。

Bounding boxes are typically axis-aligned and Oriented boxes are much less common
如上图中,如果我们想要检测棒球棍(此时是倾斜的),我们用一个与轴平行的框会将棒球棍包围起来(蓝色的框),而不是恰好把这个棒球棍包起来

- 模态检测(“Modal” dection): Bounding boxes cover only the visible portion of the object 模态检测中,边界框只覆盖可见的物体部分,即检测框的范围仅包括图像中可以看到的那部分物体
- 非模态检测(Amodal dection): box covers the entire extent of the object even occluded parts 非模态检测中,边界框覆盖整个物体的范围,包括被遮挡的部分。换句话说,框不仅包括可见部分,还假设出物体的被遮挡区域。
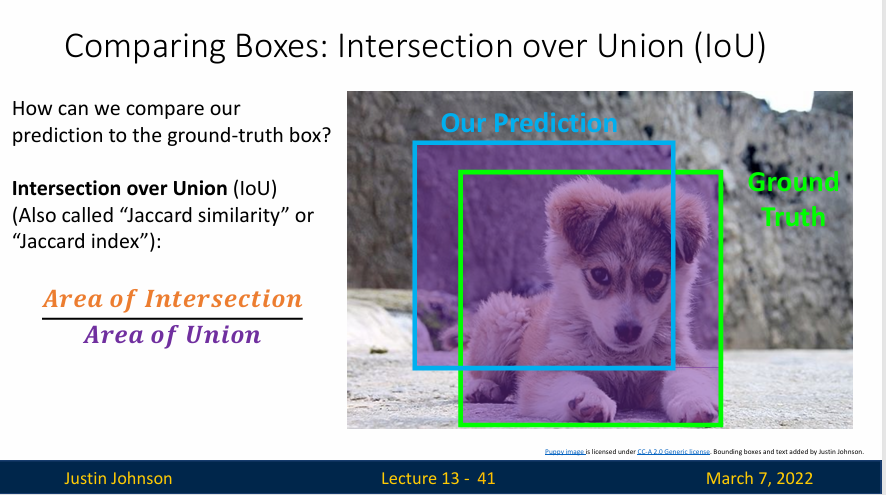
我们使用算法预测了一个边界框,但是我们如何去判断这个边界框是否位置和大小都合适呢?所以我们需要使用一种叫做Intersection over Union(IoU)的方法去进行对比,我们使用这种方式去计算两个盒子之间的相似性
首先,我们计算两个边界框的交集,也就是图像中橙色的部分,然后计算两个边界框直接的并集(有点类似于和空间的概念),也就是图像中的紫色部分,可知计算结果是一个0-1之间的数字(这个叫做交并比或者IoU),而且数字越高,边界框之间的匹配程度越好
我们通常用四个参数来描述这个边界框,\(x\) 和 \(y\) 描述框的中心位置,\(w\) 和 \(h\) 描述框的高和宽,当然我们可以使用其他形状的边界框或者使用旋转的边界框,但是为了标准化,我们统一使用方形边界框,原因如下:
- 参数量少,只有四个参数,计算量小。
- 便于进行裁剪、缩放等图像处理
- 泛化能力强,虽然方形边界框可能不能完全匹配目标的形状,但它能够提供足够的信息来识别和定位目标。对于大多数实际应用来说,完全匹配目标形状的精确边界框并不是必需的
- 兼容性好,大多数目标检测的数据集(如PASCAL VOC、COCO等)都是使用方形边界框进行标注的。使用方形边界框可以确保模型和数据集的兼容性。
一旦从图像分类转向目标检测,我们需要处理的最大问题之一就是如何完成多输出任务,这也是第一个挑战,在图像分类中,模型总是为每个图像做一个单一的输出,一个单一的类别标签
现在有了图像分类,就需要为了一个图像需要输出一整套检测到的对象,每个图像可能有不同数量的检测到的对象,所以现在我们需要以某种方式建立一个模型,它可以输出大小不一的检测结果

第二个挑战是如何产生两种类型的输出,标签和边界框。
第三个挑战是在目标检测任务中,我们通常会面临更高分辨率的图像。
我们先从一个最简单的情况开始,检测一个只有单一目标的图像。
比如说,我们有一张图片(如下图所示),其中只有一个猫(我们想检测的对象),我们运行一个训练好的CNN,比如说VGG或者ResNet这些,然后得到一个4096维的特征向量,在传统的图像分类任务中,我们只需要使用这个特征向量进行分类即可,但是在这里我们会将其分为两路,一个用于分类,一个用于输出边界框
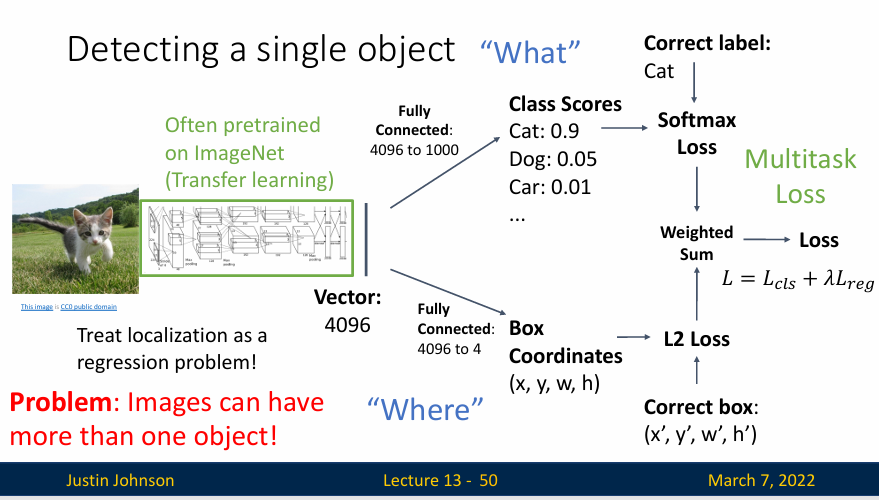
我们使用一个全连接层将特征向量降维到四维,也就是边界框的坐标,然后使用损失函数进行训练,比如说L2正则化损失,然后就有两个损失函数,因为我们要求我们的模型预测两种不同的事物,但为了计算梯度下降,我们实际上只需要以单个标量的损失函数来完成,所以我们只能将两个损失函数加权求和,得到一个总的损失函数,以此来克服这个问题
这么做的原因主要有两个:
- 捕捉不同的任务目标:在目标检测任务中,我们的目标是识别出图像中的对象(分类任务),并确定它们的位置(回归任务)。这两个任务有不同的目标,因此需要不同的损失函数来衡量模型在这两个任务上的表现。通过将这两个损失函数结合起来,我们可以同时优化模型在两个任务上的表现来得到一个多任务模型。
- 权衡不同任务的重要性:不同的任务可能需要不同的权重。例如,对于某些应用,准确地确定对象的位置可能比正确地分类对象更重要。在这种情况下,我们可以通过增大回归损失的权重,使模型更重视位置预测的准确性。权重的选择通常需要基于实际问题和数据进行调整。
检测一个对象是很简单的,但是目标检测的困难之处是如何检测多个对象,对象的数量是不定的,所以我们需要从网络模型中输出很多不同的数字,或者说我们需要模型为图像中可能看到的每个不同物体输出可变数量的对象,有一种相对简单的方法可以做到这一点,称为目标检测的滑动窗口方法
我们的想法是,假设一个有了一个训练好的CNN,让它对输入图像的窗口或者说子区域进行分类,每个子窗口输出一个类别,但是注意一下,如果我们想检测N个类别,那么实际上的输出是N+1个类别,额外增加的一个是背景类别

但是着带来一个问题,对于一个 \(H\times W\) 的图像,他需要多少个窗口呢?考虑窗口大小 \(h\times w\) ,那这个问题的答案是:\((W-w+1)\times (H-h+1)\) ,因此所需要的窗口数为
这是显然一个非常大的数字,所以我们需要改进我们的办法。一个思路是在在图像每个可能区域上评估目标检测器,也就是候选区域(Region Proposals)

- Find a small set of boxes that are likely to cover all objects
- Often based on heuristics: e.g. look for “blob-like” image regions
- Relatively fast to run; e.g. Selective Search gives 2000 region proposals in a few seconds on CPU
使用算法在图像中生成一组候选区域,以便候选区域给出一个相对小的集合,这些区域很可能覆盖图像中的所有对象
当然,这只是一个想法,并且最终会被神经网络所取代,所以无需过多关注
R-CNN
R-CNN (region-based CNN) 的工作方式非常简单:从输入图像开始,然后运行候选区域方法,比如说选择性搜索,然后选择性搜索会给出一些图像中的候选区域(可能根据图像的颜色。纹理、大小等特征提出数百甚至上千个候选区域),这些候选区域可能是不同大小和不同纵横比,所以我们需要将每个候选区域变为统一的224x224大小(需要图像放缩的方法),然后单独输入到CNN中进行分类,然后由分类结果判断是否包含对象(或者只是背景)
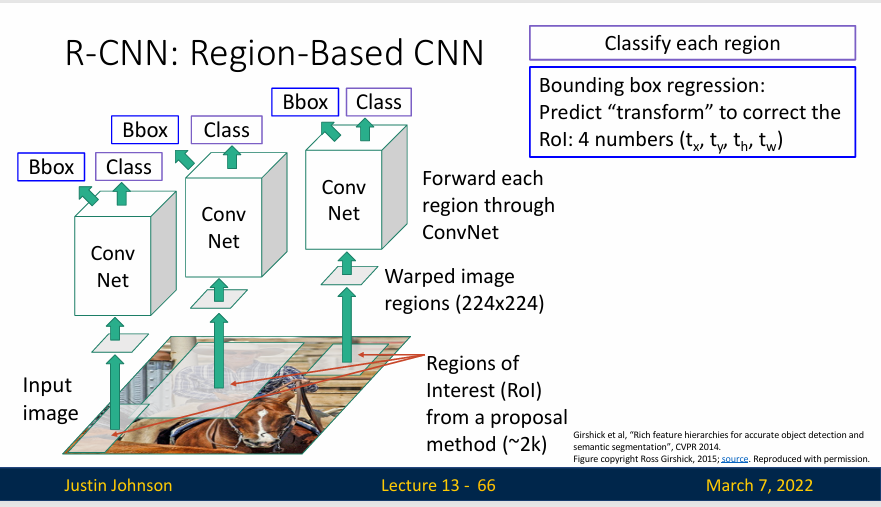
但是,上面的方法不足以解决所有问题,比如说候选区域与我们想在图像中检测的对象不完全匹配,例如一个候选区域里面包含了一个马的一部分,另一个区域包含了另一部分这样子,而且这里的边界框只不过是完成了输出,输出的边界框没有进行学习
所以我们需要改善我们的方法,也就是使得输出的边界框可以自我学习,或者说我们应用一个新的损失函数来进行学习
CNN还要输出一个额外的变换,将候选区域框转换为我们实际需要的包含目标的最终框,或者说这是一个回归的想法,我们想修改候选区域,让其可以适应图像中的目标
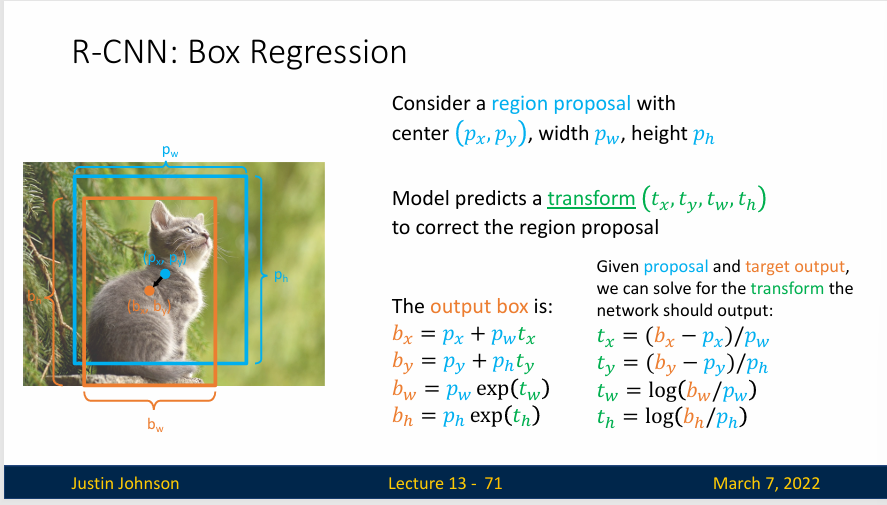
考虑一个中心点为 \((p_x,p_y)\)的候选区域,宽 \(p_w\),高 \(p_h\),模型会预测一个变换(transorm)\((t_x,t_y,t_w,t_h)\) 来修正原有的候选区域
所以输出的边界框定义成如下形式:
- \(b_x= p_x+p_wt_x\)
- \(b_y=p_y+p_ht_y\)
- \(b_w=p_w \exp (t_w)\)
- \(b_h=p_h \exp (t_h)\)
L2正则化在物体检测任务中起到了一种“平滑”的作用,它鼓励模型尽量保持候选框的原始特征不变,只做必要的小幅调整,从而增强模型的稳定性并减少不必要的偏移。这种特性有助于防止模型因为过拟合而对候选框做出过于剧烈的调整。CNN通过在裁剪的局部图像中编码候选框和输出框的相对差异,来应对尺度和位置变化的挑战,从而实现对尺度和平移的不变性。这种方法允许CNN在不同场景下处理位置和大小各异的对象,提高模型的识别效果和鲁棒性
总的来说,R-CNN的步骤如下
- 对输入图像使用 选择性搜索 来选取多个高质量的提议区域 。这些提议区域通常是在多个尺度下选取的,并具有不同的形状和大小。每个提议区域都将被标注类别和真实边界框;
- 选择一个预训练的卷积神经网络,并将其在输出层之前截断。将每个提议区域变形为网络需要的输入尺寸,并通过前向传播输出抽取的提议区域特征;
- 将每个提议区域的特征连同其标注的类别作为一个样本。训练多个支持向量机对目标分类,其中每个支持向量机用来判断样本是否属于某一个类别;
- 将每个提议区域的特征连同其标注的边界框作为一个样本,训练线性回归模型来预测真实边界框。
当然,R-CNN的这种方式是非常慢的,因为我们需要进行两千次的前向推理,所以我们需要想一些方法来减小计算量。
RNN Test-Time
- Run proposal method
- Run CNN on each proposal to get class scores, transforms
- Threshold class scores to get a set of detections
但是也带来了两个问题:
- CNN often outputs overlapping boxes
- How to set thresholds ?
NMS
目标检测器会输出非常多的框(这个也是原始输出),这些框的数量会远超图像中目标的数量,同时可能会在同一个物体的不同位置产生多个边界框。这些边界框可能会有很大的重叠,而我们通常只希望保留一个边界框来表示一个物体。因此,我们需要一种方法来去除这些重叠的边界(或者选出最合适的边界框,消除冗余边界框),也就是使用非极大值抑制(Non-Max Suppression,NMS) 的方法去筛选出最合适的边界框

以上面这张图为例,图像中有两个目标(都是狗),但是有四个原始边界框,每个边界框都带有不同的分类概率(概率由CNN计算),那么我们如何进行筛选呢?
- 对所有候选的边界框根据其得分(一般是模型预测的置信度或类别概率)进行降序排序,选取得分最高的边界框,并将其加入到最终结果列表中
- 计算这个得分最高的边界框与其他所有候选边界框的交并比,移除那些与得分最高的边界框具有高交并比(通常设定一个阈值或者threshold,例如0.7)的所有候选边界框
- 如果还有其他边界框存在,继续上面的处理
NMS的基本思想是,对于重叠的边界框,我们只保留得分(例如,目标检测模型预测的置信度或类别概率)最高的一个,同时抑制(即删除)其他的边界框。在实际操作中,我们通常会设置一个交并比(Intersection over Union, IoU)阈值,如果两个边界框的IoU超过这个阈值,那么得分较低的边界框就会被删除。
通过NMS,我们可以有效地减少冗余的边界框,使得每个物体只被一个边界框表示,从而提高了目标检测的准确性和效率(如下图所示)。

这是一个十分合理的算法,并且基本上所有的目标检测算法都依赖于某种非极大值抑制算法来消除冗余边界框,当然,非极大值抑制算法也有一点问题,那就是如果图像中有很多高度重叠的对象,会造成一些麻烦,而且实际上并没有一个很好的解决方法.
mAP
我们前面找到了IoU这种方法来判断物体检测器在在单个图像上的性能表现,但是我们还需要一种在数据集上评价物体检测器表现的指标,也就是mAP指标,mAP则是所有类别AP值的平均,它能够反映出模型在整个数据集上的整体性能。
平均精度(AP):
- 对于单个类别,首先计算该类别的精度(Precision) 和召回率(Recall)。精度表示预测框中真正为目标物体的比例,召回率表示所有真实目标物体中被检测出来的比例
- 以不同的的阈值来判断预测框是否为正样本,从而得到一系列不同精度-召回率值,并在精度-召回率曲线上计算曲线下的面积(AP)
计算mAP的方法如下
- 在所有测试图像上运行物体检测器(用NMS)
- 对于每个类别,计算平均精度(AP),
- 对于该类别中的每个检测(从最高分到最低分,检测结果来自于整个测试数据集)来说
- 如果它与一些GT边界框(Ground-Truth Box) 相匹配,且IoU>0.5,将其标记为正并且认为这是一个正确的检测,并消除该GT边界框
- 如果不能匹配任何一个GT边界框,那么标记为负值
- 基于检测是否正确,在PR曲线上画出一个点(如下图所示) ![[Pasted image 20241028090613.png]]
- 不过这里的计算方式是累计的,比如说第一个 0.99 置信度的检测匹配了一个GT 边界框,那么就算一个正样例;第二个 0.95 置信度的检测匹配了另一个 GT 边界框,再次画点的时候是加上之前的计算的。
- 平均精度(AP)就是PR曲线下的面积,是一个 0 到 1 的数,比说在这里狗类的AP就是0.86
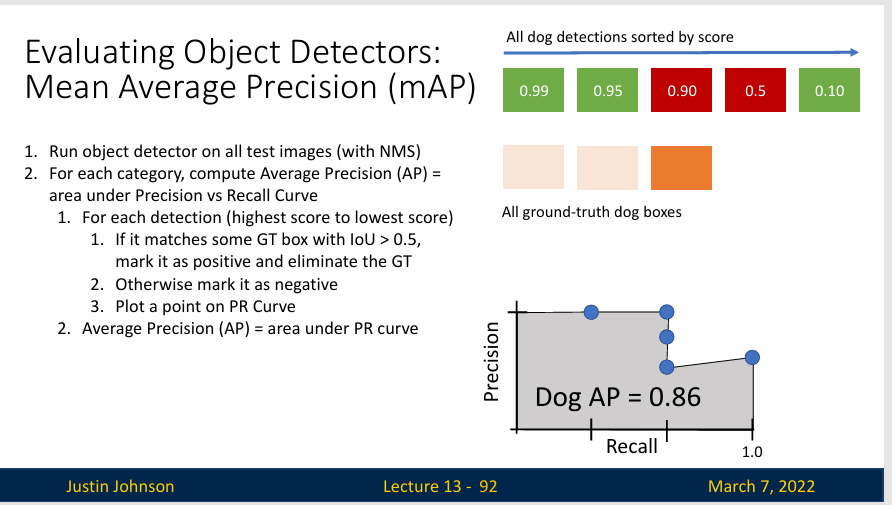
- 对于该类别中的每个检测(从最高分到最低分,检测结果来自于整个测试数据集)来说
- 平均精度 (MAP) 就是所有类别的平均精度的平均数
至于为什么使用这种指标来评估物体检测器,那是因为对于不同的程序,你可能希望有不同的选择,你可能需要不同的权衡,比如说在自动驾驶中不希望误判任何周围物体,或者在某些程序中,误判是可以容忍的,所以不同的用例需要不同的阈值和精度之间进行权衡
但通过计算这个平均精度指标,它总结了精度和召回之间权衡的所有可能点,所以这就是为什么人们倾向于使用这个指标来评估对象检测
实际上,mAP的优点如下:
- 全面性:mAP考虑了检测模型的查准率(Precision)和查全率(Recall),这两个指标反映了模型在精确性和覆盖率方面的表现。只有当模型在这两方面都表现良好时,mAP值才会高。
- 平均性:mAP是所有类别的平均精度(AP)的平均值,因此它能够反映模型在整个数据集上的总体性能,而不仅仅是在某个类别或某个图片上的性能。
- 稳健性:在目标检测任务中,预测结果的置信度阈值的选择可能会对模型的性能产生很大影响。mAP通过对所有可能的阈值进行平均,使得模型的性能评估更加稳健,不受阈值选择的影响。
- 易于比较:mAP提供了一个单一的、范围在0到1之间的分数,因此它很容易用来比较不同模型的性能。
- 广泛接受:mAP是目标检测任务中最常用的性能评估指标,许多比赛和研究论文都使用它来评估模型的性能。因此,使用mAP可以方便地与其他模型进行比较。
但是他也有如下缺点:
- 计算较为复杂,尤其在多类别、大规模数据集
- 对于小物体检测和遮挡物体检测,mAP 可能不完全反映模型效果。
Summary
- Transfer learning allows us to re-use a trained network for new tasks
- Object detection is the task of localizing objects with bounding boxes
- Intersection over Union (IoU) quantifies differences between bounding boxes
- The R-CNN object detector processes region proposals with a CNN
- At test-time, eliminate overlapping detections using non-max suppression (NMS)
- Evaluate object detectors using mean average precision (mAP)