OpenMP&MPI
约 2296 个字 151 行代码 4 张图片 预计阅读时间 17 分钟
OpenMP
- UMA(Uniform memory access):CPU 访问内存的延迟相同或相近
- NUMA(Non-uniform memory access):CPU 核心访问两块内存的延迟不一样
OpenMP provides us an easy way to transform serial programs into parallel
| C | |
|---|---|
编译这段代码时需要做如下指定:(不然会编译失败)
| Bash | |
|---|---|
这段代码和传统C语言代码的不同之处有:
- 引用了 OpenMP 的头文件
#include<omp.h> - 预处理指令:
#pragma omp parallel - 并行域(
{...}中的内容)
OpenMP 是基于线程的并行编程模型,采用 Fork-Join 的并行执行方式。程序开始于一个单独的主线程(Master Thread),然后主线程串行执行(串行域),直到遇到第一个并行域(Parallel Region),然后开始并行执行并行域,执行完后再回到主线程,执行串行域,直到遇到下一个并行域。
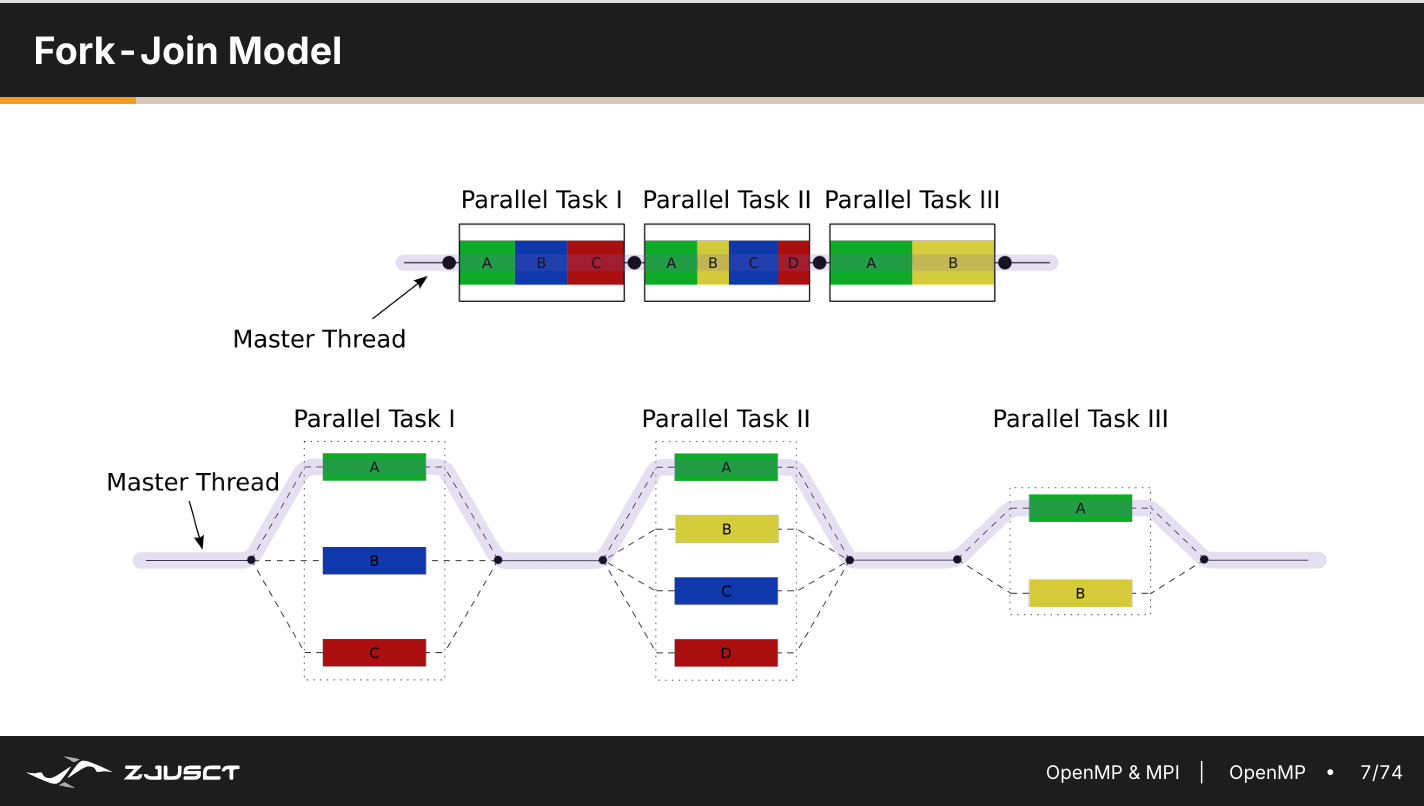
- 线程共享:代码段,堆
- 线程区别:独一无二的 ID (TID=0 为主线程)
A legal OpenMP Directive must has the folloing format(C/C++):
| Pragma | Directive | [clause[[,]clause]...](指导 Directive) |
|---|---|---|
| #pragma omp | parallel,atomic,critical,... | 0 to many |
例如:
| C | |
|---|---|
此时 Directive 选择 parallel,而后面的 cluase 告诉编译器一些具体实现的细节。注意指令对大小敏感(C语言),需要用 {} 将需要并行的代码包起来。
- Work-distribution constructs:工作分配结构,用于在多个线程间分配任务
- single 在所有线程中的一个线程执行,类似于串行执行(一些数据结构不是线程安全)
- section 每个section里面是独立的代码,有不同线程执行,可精细控制每个线程的内容
- for 自动将循环的迭代次数分配给不同线程,适用于没有数据依赖的时候
Overhead:为了完成某个特定任务所需要的额外或间接的计算时间、内存、带宽或其他资源的总和。我们在进行线程创建和调度需要花费额外的时间,这些时间会影响我们的并行效果,使得并行效果低于预期效果,由于种种原因,overhead 确实存在,而且有时候比较难避免。但是一些 overhead 可以通过编程技巧改进。
考虑每个线程上 workload 不相同的情况,比如说计算阶乘,计算 \(1!\) 的阶乘会比计算 \(n!\) 的阶乘快,这会导致 workload 比较小的任务结束后,OpenMP 会使这些线程停住等到 workload 比较大的任务执行完毕,这就会导致一个性能浪费。
- 调度选项
schedule主要控制迭代任务在线程之间的分配:- static:将所有迭代平均切分为固定大小块,按顺序分配给线程,减小 overhead,无法解决 workload 问题
- dynamic:关注任务完成情况,减小线程空闲时间,但是需要频繁调度,增加了 overhead
- Auto:将一切交给 OpenMP(x)
对于嵌套的 for 循环,如果希望嵌套内部的for循环也是并行计算,可以使用 collapse 指令,如:
| C | |
|---|---|
Shared Data and Data Hazards
并行时,由于一部分数据内存是共享的,所以可能会出现一种情况是:一个线程调走了数据并进行改写,此时另一个线程也调走了数据并进行改写,当这个线程调回数据时,会覆盖之前线程的调回的内容(或被覆盖),这就会导致一个不可预测的现象,这种情况称为 Data Hazards 。
- 解决办法:
- 将共享数据变成区域内独立的变量。(但这个并不能解决上面的问题,却能有其他效果)
- 临界区 Critical Section:相当于在并行内容中加了一个 {} 相当于改成串行执行,但是结果会比单纯串行结果慢,适用于复杂数据结构操作 Based on locking
- 原子操作 Atomic Operations :原子化指令,将拆分的指令变成一条指令,确保更新不可被中断,只适用于简单操作 Based on hardware atomic operations
- 归约 Reduction:将多个数据汇总成条数据,用在多重循环 only synchronize in the end
| C | |
|---|---|
Pitfalls & Fallacies
False Sharing(伪共享)是指当两个线程访问的变量在同一个缓存行里时,即使它们操作的是不同的变量,只要其中一个线程写了这块缓存行,就会导致另一个线程的缓存失效,触发频繁的数据同步(如缓存一致性协议),大大降低性能。
How to Optimize a program with OpenMP
- Where: Profiling
- Why: Analyze data dependency
- How: Analysis and Skills
- Sub-task Distribution
- Scheduling Strategy
- Cache and Locality
- Hardware Environment
- Get Down to Work: Testing
Tip
- Ensure correctness while parallelizing
- Be aware of overhead
- Check more details in official documents
MPI
MPI(Message-Passing Interface)是一组用于并行应用进程间的通信的接口。
A communicator defines a group of processes that have the ability to communicate with one another. Each process has a unique rank. 我们用 rank 表示不同的进程。
- MPI_COMM_WORLD:所有进程。
- MPI_COMM_SPLIT:将进程分成几个组
阻塞与非阻塞函数
- Blocking 阻塞:会等待事件完成后再执行线程
- Non-blocking 非阻塞:不会等待事件完成再执行线程
Messages are non-overtaking 保证消息传递是有序,但无法保证消息发送的公平性。
Point-to-Point communication
点对点的交流主要用到两个函数:MPI_Send 和 MPI_Recv
| C | |
|---|---|
- buf 是要发送的 buffer 的首地址
- count 是 buffer 中元素的个数
- datatype 表示发送的 buffer 中的元素类型
- 写法一般是 MPI_< 类型大写,下划线分隔 >,例如 MPI_INT、MPI_UNSIGNED_LONG_LONG
- dest 是发送目标的 rank
- tag 是 message tag
- comm 是 communicator,一般直接传 MPI_COMM_WORLD 即可
| C | |
|---|---|
- buf 是要将接收到的内容存入的 buffer 首地址(作为“输出”)
- count 是要接收的 buffer 元素个数
- datatype 是要接收的 buffer 中元素类型
- source 是接收来源的 rank(或者 MPI_ANY_SOURCE)
- tag 是 message tag(或者 MPI_ANY_TAG)
- comm 是 communicator
- status 是接收的状态结构体(作为“输出”)
- 不需要时填写 MPI_STATUS_IGNORE
- MPI_Status 中包含三个成员变量:MPI_SOURCE、MPI_TAG、MPI_ERROR
- 可以通过 MPI_Get_count(MPI_Status status, MPI_Datatype datatype, int count) 函数来获取 count
MPI_Ssend 和 MPI_Recv 都是阻塞函数,在相互使用时会进入一个死锁状态,两个阻塞函数再等待对方信息。(Deadlock means that processes pathologically wait for each other in a circle. As such it is not directly associated with blocking. ——Wikipedia)
| C | |
|---|---|
MPI_Ssend 要求对方必须调用了匹配的 MPI_Recv 才会返回,而MPI 要求在执行时才能接受消息。以两个进程为例,这两个进程都先执行 MPI_Ssend ,都在等对方调用 Recv 结果就是两个都处于等待状态,谁也没有办法继续执行,导致程序死锁卡住 一个解决方法是使用替换:
| C | |
|---|---|
MPI 为了避免这种情况提供了 MPI_Sendrecv ,将发送和接受合并起来。
| C | |
|---|---|
The buffers used for send and receive must be different。
或者采用非阻塞函数 MPI_Isend ,同时使用 MPI_Test 确保信息接受,发送数据还可以进行其他计算。
| C | |
|---|---|
| C | |
|---|---|
MPI_Test 用于检查通信是否完成,将 request 作为输入,flag 和 status 作为输出,
MPI_Wait 用来等待 request 对应的通信完成。
将一个阻塞函数拆分成一个非阻塞函数和Wait函数的好处:
- 避免死锁
- 在非阻塞函数和 Wait 函数插入其他指令,充分利用 CPU 时间。
Collective Communication
MPI_Barrier 显式的阻碍,直到 communicator 中所有进程都运行到 Barrier 之后再一起继续运行。
MPI_Bcast 指令实现了一个类似广播的效率,假如我们有八个节点,将数据从一个节点传输到剩下七个节点,采用传统 Send/Recv 方法需要进行七次操作,但是采用 MPI_Bcast 的方法只需要三次操作(一个节点-> 两个节点->四个节点-> 八个节点)
| C | |
|---|---|
MPI_Scatter 指令与 Broadcast 不同的是,每个进程收到的是 sendbuf 的一部分
| C | |
|---|---|
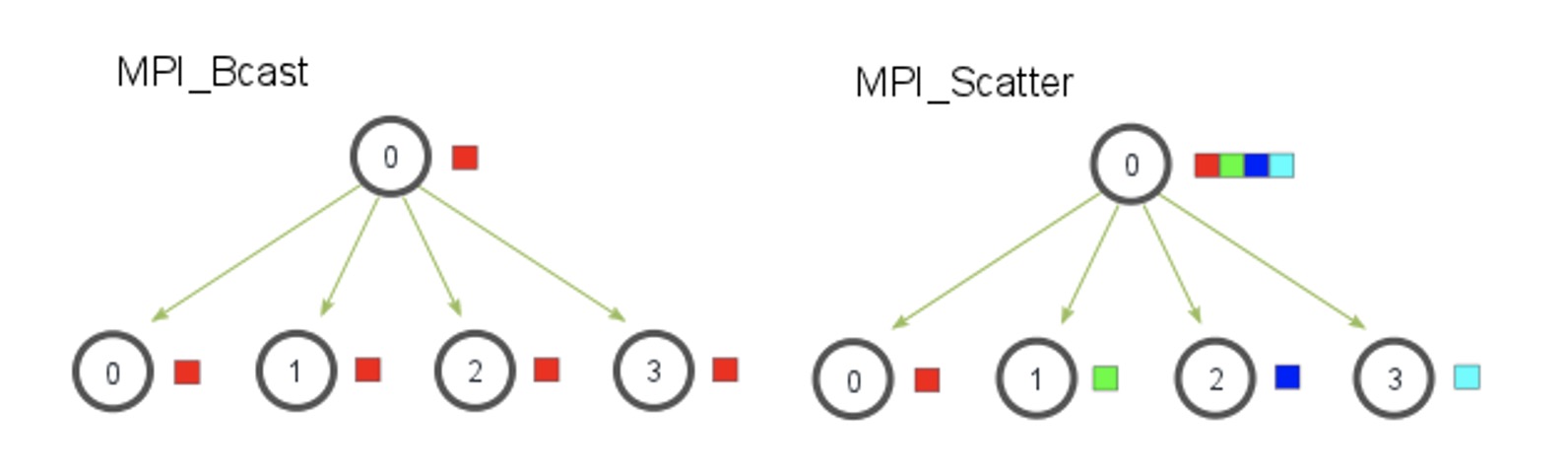
MPI_Gather 会将不同线程中的数据重新收集起来
| C | |
|---|---|
MPI_Allgather 相当于先做一个 MPI_Gather 然后再做一个 MPI_Bcast ,确保所有进程都能拿到所有数据
| C | |
|---|---|
上面的操作只是实现了对数据的收集与分发,但不对数据进行操作,MPI_Reduce 可以实现对数据的操作:
| C | |
|---|---|
MPI_Op 可以是 MPI_MAX MPI_MIN MPI_SUM MPI_PROD MPI_LAND(逻辑与)MPI_BAND(位与)MPI_LOR MPI_BOR MPI_LXOR MPI_BXOR MPI_MAXLOC(最大值与位置)MPI_MINLOC
下面的代码是用 MPI 实现分布式平均值计算的例子。MPI_Scatter 将主进程的 buffer 按块分发到所有进程的 local_buffer 中,每一块进程进程计算自己的平均值,最后利用 MPI_Reduce 进行一个求和归约,将结果放在 rank 0 的 global_avg 中
Miscellaneous
MPI 内部是一个层次化的结构。每一层都有不同的组件,每一个组件都负责不同的事情。
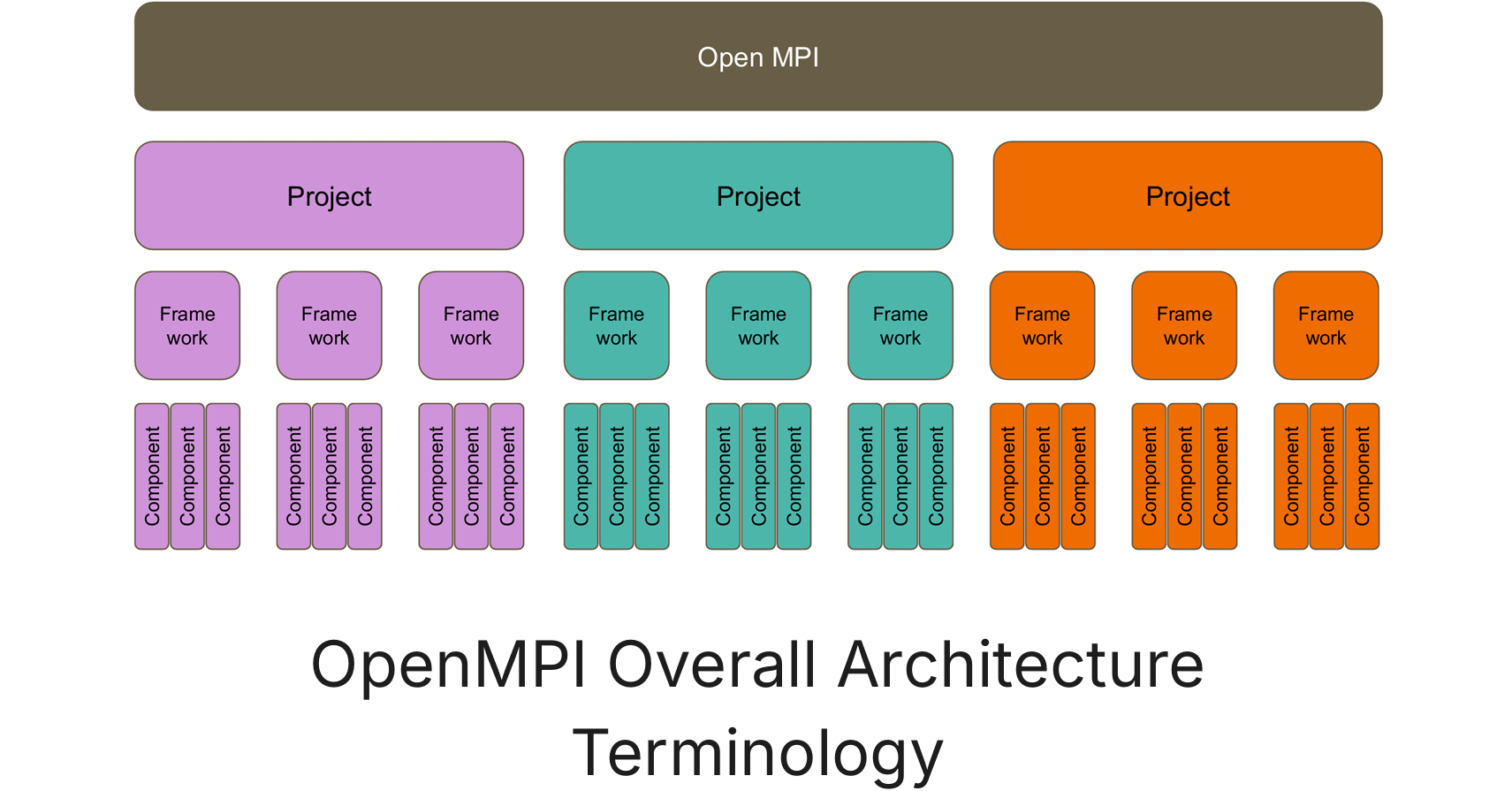

对 MPI 的调整
- 编译器
- CUDA 支持
- 通信库
- 静态还是分享数据
mpirun:
- -x [env]
- -bind-to core
- -hostfile [hostfile]